奐敪擔帍(44)
僩僢僾傊栠傞
奐敪擔帍僀儞僨僢僋僗傊
慜偺儁乕僕傊
師偺儁乕僕傊
偦偆偄偊偽丄奐敪擔帍偺峏怴傪偟偰偄側偐偭偨丅
幚偼10寧偐傜嶳棞偵揮嬑偵側傝丄扨恎晪擟偲側傝傑偟偨丅嶳棞偵棃偰婛偵侾儢寧丄偙傟偐傜姦偄搤傪寎偊傛偆偲偟偰偄傑偡丅
扨恎晪擟椌偑柍偄偺偱丄晹壆傪庁傝偰壠捓曗彆傪傕傜偭偰廧傓偲偄偆僗僞僀儖偵側傝傑偡丅
愭偵扨恎晪擟偵棃偰偄傞桭恖傗忋巌偺榖傪暦偄偰丄峛晎墂偐傜曕偄偰偄偗傞斖埻偱壠傪扵偟傑偟偨偑丄怓傫側忦審偐傜偪傚偭偲峀偡偓傞2LDK偺晹壆偵側偭偰偟傑偄傑偟偨丅
偝偡偑偵壠捓偑婯掕妟傪偼傞偐偵僆乕僶乕偟偰偟傑偆偺偱偡偑丄嫹偄巚偄傪偡傞偺偼儎僟側偲巚偄傑偟偰帺屓晧扴偡傞偙偲偵丅
偦偺偍偐偘偱丄峀乆偲嬻娫傪巊偆帠偑偱偒偰傑偡丅
峀偄偗偳侾恖廧傑偄偩偟丄僆乕儖僼儘乕儕儞僌偱傎傏僶儕傾僼儕乕丅儂乕儉儘儃僢僩偺尋媶奐敪偵偼傕偭偰偙偄偺娐嫬偵側傝傑偟偨丅
尰幚偵偼丄偪傚偭偲僗儔僽岤偑敄偦偆側偺偱儘儃僢僩偑偪傖偑偪傖曕偐偣傞偭偰傢偗偵偼偄偐側偄偱偡偑丅
偝偰丄儔儉僟丅
摦椡妛僼傿儖僞乕偑偱偒偨偺偱丄幚婡幚憰偵恑傒偨偄偲偙傠偱偡偑丄幚婡偵幚憰偟偰崱傑偱偺僔儈儏儗乕僔儑儞傒偨偄偵悢曕偩偗曕偐偣傞偩偗偲偄偆偺傕柺敀偔側偄偺偱丄帺桼偵曕峴偱偒傞傛偆偵僾儘僌儔儉傪奼挘偡傞昁梫偑偁傝傑偡丅
崱偼丄曕偒弌偟偐傜掆巭偡傞傑偱偺曕峴寁夋傪棫埬偟丄偦偙偵岦偗偰曕梕傪惗惉偟側偑傜摦偔偲偄偆偙偲偵偟偰偄傑偟偨丅
摦椡妛僼傿儖僞乕傪巊偆偨傔偵偼枹棃偺曕峴寁夋偑昁梫偱偡丅掆巭傑偱偲偼尵傢側偄偗傟偳1昩愭偔傜偄偼昁梫偵側傝傑偡丅
帺桼偵曕峴偲偄偆偙偲偼曕峴寁夋偑傑傑側傜側偄偲偄偆偙偲側偺偱丄搒搙曕峴寁夋傪捛壛偟偰偄偔昁梫偑偁傝傑偡丅
偡傞偲丄梊尒崁偑巊偊側偔側傞僔乕儞偲尵偆偺偑昁偢弌偰偔傞偺偱丄怴偟偄曕峴寁夋偱梊尒崁傪嵞峔抸偡傞偲偄偆巇慻傒偑昁梫偵側傝傑偡丅
偦偺偁偨傝偺嶌傝崬傒偑昁梫偵側偭偰偔傞丄偲偄偭偨忬嫷偱偡丅
枹抦偺曕峴寁夋偲尵偭偰傕丄曕暆傪曄偊偨傝儁乕僗傪曄偊偨傝偩偗偠傖柺敀偔側偄偺偱僇乕僽曕峴傪慻崬傒傑偡丅
僇乕僽偭偰堄奜偲柺搢偱嵍塃偱侾曕偺挿偝偑堘偆偲偐丄儘儃僢僩偺曽岦傪彊乆偵曄偊側偒傖側傜側偄偲偐丄僆僼儔僀儞曕梕惗惉偺帪偵寢峔側嶌傝崬傒傪偟傑偟偨丅
偦偺偍偐偘偱儘儃僢僩巔惃偺娗棟娭悢傗傜栚昗ZMP楍惗惉娭悢傗傜偼僆僼儔僀儞偺帪偺偑偦偺傑傑巊偊傑偡丅
儂價乕儘儃僢僩偺奅孏偱愄偐傜拲栚偟偰偄傞偺偑丄僊傿偝傫偲幠揷偝傫偺曕峴儌乕僔儑儞偱偡丅
僊傿偝傫偼嵟嬤偼僟儞僗堦曈搢側偺偱傾儗偱偡偗偳丄幠揷偝傫偺僽儔僢僋僒儞僟乕偺曕峴偼偄偮傕尒偰偄偰椳偑弌傞掱偡偽傜偟偄偲巚偭偰傑偡丅
偁偦偙傑偱僰儖僰儖偲旤偟偔曕偗傟偽丄偁傞庬姰惉偺堟偵偁傞偺偱偼側偄偐偲巚偄傑偡丅丂偁偺僒僀僘偺儘儃僢僩偩偲偁偺懍搙偱曕偗側偒傖僟儊偐側偲丅
偱丄GoSimulation忋偩偲柍棟偵摦偐偟偰傕夡傟側偄偺偱儁乕僗0.2昩偱偱偒傞偩偗戝屢偱曕偐偣偰傒傑偟偨丅
寢壥丄慡慠僟儊偱偡丅丂傑偢丄儘儃僢僩偺懌偺壱摥斖埻偑戝偒側曕暆偵懳墳偟偰偄側偄丅旼瞎尴罐曕峴偱僇僢僐埆偄丅
峏偵丄偙偺懍搙偱摦偐偡偲儓乕儌乕儊儞僩偑彴柺偺僌儕僢僾傪忋夞偭偰偟傑偆傜偟偔丄傑偲傕偵曕偗傑偣傫丅
懌偺壱摥斖埻偑嫹偄偺偼傢偐偭偰偄偨帠偱丄崱夞偙偺傾僀僨傿傾偱幚婡傪嶌傞帠傪桪愭偟偨偺偱傂偲傑偢掹傔傑偟傚偆丅偦偺偆偪峫偊傑偡丅
儓乕儌乕儊儞僩偵偮偄偰偼亂偲偆偲偆亃榬怳傝偱儌乕儊儞僩僉儍儞僙儖傪偟偰傒傑偡丅
偲偄偆偺傕丄俀懌曕峴儘儃僢僩偵庢慻傒弶傔偰悘暘偲偨偪傑偡偑丄幚偼曕偐偣傞帪偵榬傪怳傜偣偨偙偲偑偁傝傑偣傫丅
偦偙偵億儕僔乕偑偁傞傢偗偠傖側偔偰丄榬傪怳傜側偒傖曕偗側偔側傞偔傜偄偺懍搙偱曕偐偣偨偙偲偑側偄偺偑懡暘尨場偩偲巚偄傑偡丅
偁偲丄榬偭偰寢峔栵夘偱丄媡僉僱寁嶼偱摦偐偡偺偵惂栺傪怓乆偮偗側偄偲寁嶼偑戝曄側検偵側偭偨傝偟傑偡丅
仈偙傟偼榬偺愝寁偵埶傞偑丄忕挿側応崌偑懡偔丄捈岎幉偠傖側偄応崌傕懡偔丄媡僉僱偺夝愅夝偑摼傜傟側偄応崌傕偟偽偟偽丅丅
丂懌偺応崌偼乽暯偨傫側彴偵棫偮乿側偳偺惂栺傪梌偊傞帠偱寁嶼偑娙棯壔偝傟傞働乕僗偑偁傞偺偩偑丄丄丅
偦偙偵懳偟偰帺暘偱暊棊偪偡傞曽朄偑尒偄偩偣側偐偭偨偨傔丄偲偄偆偺傕偁傝傑偡丅
妬揷愭惗偺嫵壢彂偵偼儌乕儊儞僩偵偮偄偰偺寁嶼傕峫椂偟偰偄傑偡偺偱丄傕偪傠傫儔儉僟偺ZMP寁嶼娭悢偵傕儌乕儊儞僩崁偺寁嶼幃偼慻傒崬傫偱偄傑偡丅
偱傕丄僆僼儔僀儞偺帪偵斾妑偟偨偲偙傠丄塭嬁偑彫偝偄偲敾抐偟偰崱偼寁嶼偟偰偄傑偣傫丅
偦傟傪巊偭偰丄儌乕儊儞僩傪懪偪徚偡傛偆側榬偺怳傝傪惗惉偝偣傞偲偄偆偺傕寢峔娙扨偵弌棃傞偐側偲傕巚偄傑偡丅
崱夞偼偦偙傕偡偭旘偽偟偰巟帩媟婳摴偺媡埵憡偱榬傪怳傞帠偱僉儍儞僙儖偝偣偨偄偲巚偄傑偡丅
仈榬偺桳傞柍偟偱偺儌乕儊儞僩偺嵎偔傜偄偼尒偰偍偔偐側丅
仾丂榬偺怳傝傪壛偊偨曕峴丅丂婃挘偭偰儁乕僗憗傔曕暆峀傔偵偟偰偄傑偡丅
婥晅偔偲傕偆擭偺悾丅
侾偐寧埲忋擔帍傪峏怴偟偰偄側偐偭偨丅
怴偟偄怑応偵姷傟側偄丄偲偄偆偐儕僘儉偑嶌傟側偄丄偲偄偆偐弌挘偽偐傝偱偁傑傝壠偵嫃側偄丄偲偄偆偐弌挘偵峴偔偲堸傒偵峴偭偰偽偐傝偺忋偵丄嶳棞偱傕堸傒夛偑廳側偭偨傝偱丄偁傑傝弴挷偵奐敪偑恑傫偱偄偔栿傕側偔擔偑夁偓偰傑偄傝傑偟偨丅
姰慡偵儘儃僢僩奐敪傪僗儖乕偟偰偄偨傢偗偠傖側偔丄摦椡妛僼傿儖僞乕偺幚婡幚憰偺専摙偼恑傔偰偍傝傑偟偨丅偙傟偑堄奜偲擄暔偱丄娙扨偵偱偒傞偲偼巚偭偰偄側偐偭偨偗偳丄梊憐埲忋偵傔傫偳偔偝偄丅
僆儞儔僀儞惗惉偲摦椡妛僼傿儖僞乕偼摨偠梊尒婍傪巊偭偰偄傑偡丅
僆儞儔僀儞惗惉帺懱偼扨幙揰搢棫怳巕偺塣摦曽掱幃傪巊偭偰偄傞偺偱幚婡偲偼岆嵎偑偁傝傑偡丅
偦偙偱僆儞儔僀儞惗惉偱寁嶼偟偨廳怱揰嵗昗偵側傞傛偆偵儘儃僢僩傪曕偐偣偨帪偵丄ZMP偑偳偺埵抲偵側傞偐傪懡幙揰儌僨儖傪巊偭偰寁嶼偟傑偡丅偦偺寁嶼寢壥偲丄尦乆偺ZMP寁夋偲傪斾妑偟偰嵎暘傪庢傝傑偡丅
偦偺嵎暘楍傪怴偨側栚昗偲偟偰僆儞儔僀儞惗惉偱廳怱婳摴傪寁嶼偟傑偡丅
偙傟偑摦椡妛僼傿儖僞乕偱偡丅ZMP嵎暘傪巊偭偰嵞寁嶼偟偰懌偟偙傓偭偰曽朄偼僆僼儔僀儞惗惉偲摨偠偱偡偹丅
ZMP嵎暘傪寁嶼偡傞偵偼
侾丏僆儞儔僀儞惗惉
俀丏懡幙揰儌僨儖偵傛傞ZMP嶼弌
偑昁梫偱丄丂嵟廔揑側廳怱埵抲偺嶼弌偵偼
俁丏僆儞儔僀儞惗惉
係丏ZMP嵎暘傪擖椡偲偟偨僆儞儔僀儞惗惉
偑昁梫偱偡丅
侾丏偲俁丏偼梊尒僗僥僢僾悢傪妘偰偰偼偄傑偡偑摨偠寁嶼偱偡偺偱丄俀搙寁嶼偡傞偺偼傕偭偨偄側偄丅
偦偙偱丄ZMP嵎暘傪寁嶼偟偨抜奒偱丄僆儞儔僀儞惗惉偲ZMP嵎暘傪儕僗僩偵奿擺偟偰曐懚偟傑偡丅
嵟廔揑側寁嶼傪偡傞抜奒偱ZMP嵎暘儕僗僩傪巊偭偰嶼弌偟偨曗惓検乮係丏乯偲僆儞儔僀儞惗惉寢壥儕僗僩偺堦斣屆偄僨乕僞乮侾丏乯傪巊偭偰嵟廔揑側廳怱嵗昗傪寛掕偟傑偡丅
偝偰丄曕峴寁夋偵曄峏偑惗偠偰丄偢偭偲傑偭偡偖偵曕偔偮傕傝偩偭偨偺偑丄媫偵嬋偑傟偲偛庡恖偑尵偭偰偄傞丄偲偟傑偡丅
偡傞偲丄梊尒僨乕僞偼侾昩愭傑偱梡堄偟偰偄傞偺偱丄侾昩愭偐傜嬋偑傝傑偡傛乣丄偲尵偄偨偄偲偙傠側偺偩偑偦傟偩偲奒抜偐傜揮偘棊偪傞偲偐丄庢傝曉偟偺偮偐側偄偙偲偵側傞偺偐傕偟傟側偄丅
偱偡偺偱丄懍傗偐偵曕峴寁夋偺曄峏偵墳偠傞昁梫偑偁傝傑偡丅
乮梊尒婍偺枹棃崁傪偳傟偩偗抁弅偟偰傕巊偊傞偲偐偺専摙偼柍堄枴側偺偱峴偄傑偣傫乯
僆儞儔僀儞惗惉丄懡幙揰儌僨儖偵傛傞ZMP嶼弌丄ZMP嵎暘傪巊偭偨曗惓検寁嶼丄偳傟傕懍搙丄壛懍搙傪巊偭偨寁嶼偩偟丄梊尒婍偵帄偭偰偼夁嫀僨乕僞偺椵愊傪棙梡偟偰偄傑偡丅
峏偵偼曕峴儌乕僔儑儞偺惗惉傕ZMP楍傪嶲峫偵惗惉偟偰偄傞娭學偱丄忬懺曄悢傪巊偭偰偄傑偡丅
偱偡偺偱丄偁傞忬懺傪帺桼偵嶌傝弌偡偙偲偼崲擄偱偡丅
梊尒婍偼曕偒巒傔偐傜偺忬懺傪嵞搙峴偆昁梫偑偁傝丄懡幙揰儌僨儖偼栚揑偺僼儗乕儉偺夁嫀俀僼儗乕儉偺僨乕僞偑昁梫偱偡丅
擟堄偺忬懺傪嵞尰偡傞偵偼夁嫀偺偡傋偰偺僨乕僞傪曐娗偟偰偍偔昁梫偑偁傝丄偒傢傔偰僫儞僙儞僗偱偡丅
巹偼丄彮偟寜暼徢丠側偲偙傠偑偁傝傑偟偰丄柍懯側偙偲傪傗傜側偄偨傔側傜偦偺柍懯側帠傪偡傞帪娫偺壗攞傕偺帪娫傪偐偗偰偱傕乽傗傜側偄庤抜乿傪峫偊傞偲偄偆偲偙傠偑偁傝傑偡丅
偱丄偦偺寜暼偵偐偗偰側傫偲偐寁嶼検丄儊儌儕乕検偑揔惓側庤抜偑側偄偐偲峫偊傑偟偨偑丄寢嬊偼栚偺妎傔傞傛偆側庤抜偼傒偮偐傝傑偣傫偱偟偨丅
寢榑偲偟偰偼乽摦椡妛僼傿儖僞乕寁嶼偲摨帪偵摦椡妛僼傿儖僞乕傪巊傢側偄寁嶼傪幚巤偡傞乿偲偄偆偙偲偱偟偨丅
摦椡妛僼傿儖僞乕偺梊尒崁偺寁嶼偵偼僆儞儔僀儞惗惉偑昁梫偱偡丅偱傕枹棃崁偺偨傔偵侾昩傑偱傕愭偺寁嶼傪偟偰偟傑偭偨傜偦傟傪尰忬傑偱姫偒栠偡偺偼崲擄偱偡丅乮偱偒側偔傕側偄婥偼偟偰偄傞乯偱偡偺偱丄侾昩枹棃偺寁嶼偲尰嵼偺寁嶼傪峴偄丄寁夋偑曄峏偵側偭偨傜侾昩枹棃偺寁嶼偼幪偰偰丄怴偟偄寁夋偺尦偵尰嵼偺寁嶼忬懺傪巊偭偰侾昩枹棃傑偱傪堦婥偵寁嶼偟偰枹棃崁傪嵞峔抸偟傑偡丅
懡幙揰儌僨儖偵偮偄偰偼夁嫀俀僼儗乕儉偺巔惃偝偊偁傟偽嵞峔抸偱偒傞庤抜偼偁傝傑偡偑丄偙偙偼傂偲傑偢儌乕僔儑儞惗惉傕摨帪恑峴偟傑偡丅
偦偺寢壥丄
侾丏枹棃崁
丂侾丏侾丂僆儞儔僀儞惗惉乮侾昩枹棃乯
丂侾丏俀丂惗惉寢壥傪巊偭偨曕峴儌乕僔儑儞惗惉
丂侾丏俁丂懡幙揰儌僨儖偵傛傞ZMP寁嶼佀ZMP嵎暘寁嶼
俀丏尰嵼
丂俀丏侾丂ZMP嵎暘偐傜偺曗惓検寁嶼
丂俀丏俀丂曗惓嵪僨乕僞偱偺曕峴儌乕僔儑儞惗惉乮佀偙傟偑曕峴儌乕僔儑儞乯
俁丏嵞峔抸梡
丂俁丏侾丂僆儞儔僀儞惗惉乮尰嵼乯
丂俁丏俀丂惗惉寢壥傪巊偭偨曕峴儌乕僔儑儞惗惉
丂俁丏俁丂懡幙揰儌僨儖偵傛傞ZMP寁嶼
偲丄偙傟偩偗偺偙偲傪僼儗乕儉枅偵寁嶼偟傑偡丅丂丂丂丂娫偵崌偆偺偐側丅
俁丏俀丄俁丏俁偵偮偄偰偼ZMP寁夋曄峏偵旛偊偰偺寁嶼側偺偱丄寁嶼偩偗峴偭偰寢壥偼棙梡偟傑偣傫丅
偙偺慻傒崬傒傪Go Simulation!忋偺僾儘僌儔儉偱幚尰偟偰傒傑偟偨丅
偪側傒偵丄摦椡妛僼傿儖僞乕傪巊傢側偔偰傕偙傟偔傜偄偼曕偒傑偡丅
廫暘埨掕偟偰傞丅丅傕偆彮偟僴乕僪偵摦偐偡偲嵎偑弌偰偔傞傛偆偱偡丅
幚婡幚憰偡傞偵偼峏偵壽戣偑偁傝傑偡丅
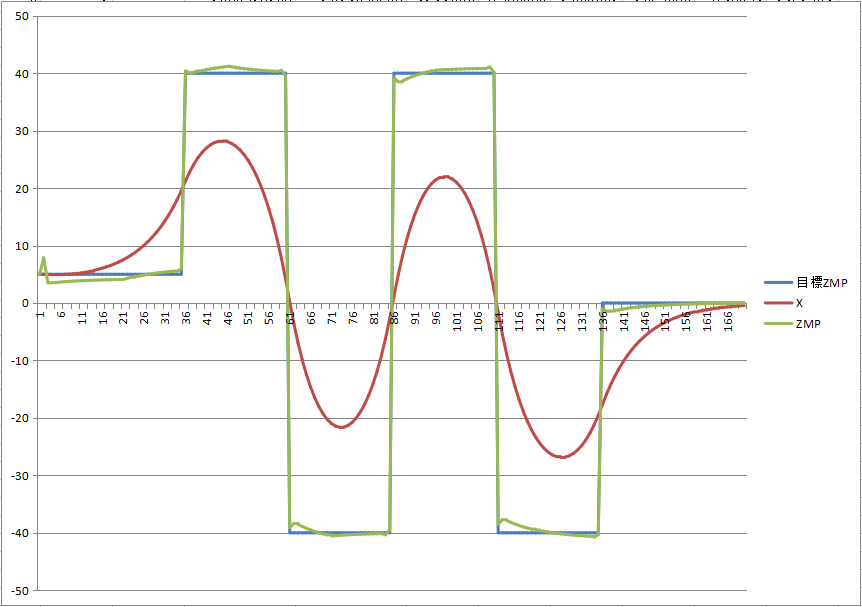
偦傟偼梊尒崁偺嵞峔抸帪娫偱偡丅栺侾昩暘偺寁嶼偑昁梫偱偡丅乮25ms廃婜偱摦偐偟偰偄偨傜40僐儅暘乯曕峴傪奐巒偡傞偲偒偵傕摨條偺寁嶼偑昁梫偱偡偑丄偦傟偼寁嶼偑廔傢偭偰偐傜曕偒弌偣偽椙偄偺偱栤戣偵側傝傑偣傫丅
曕偄偰偄傞嵟拞偵偙傟傪傗傞偲側傞偲僒乕儃偵僐儅儞僪傪憲偭偨巆傝帪娫偱峴傢偹偽側傜偢丄僆乕僶乕偼嫋偝傟傑偣傫丅
寁嶼検偑曄傢傞傢偗偠傖側偄偺偱娫偵崌偆側傜偄偮傕娫偵崌偆偟丄娫偵崌傢側偄側傜偄偮傕娫偵崌傢側偄偺偱偡偑丅
峏偵偼備偔備偔偼惂屼廃婜傪抁偔偟偨偄丅偦偺偨傔偵尰嵼偺CortexM3偐傜M4偵偟偨偄偲巚偭偰偄傞偺偵丄偦偆偡傟偽僒乕儃偺捠怣懍搙傕1Mbps偵偱偒傞偐傜5ms偔傜偄偵偼偱偒傞偐側丠偲婜懸偟偰偄傞偺偵丄FPU偑巊偊傞偐傜寁嶼壜擻検憹偊傞側丄偲巚偭偰偄傞偺偵丄梊尒崁偼40僐儅偐傜200僐儅偵憹偊傞偺偱偒偭偲媡忊偱偡丅
偱偡偺偱丄偙偺寁嶼偼妱傝崬傒僗儗僢僪偱偼側偔丄暿僗儗僢僪乮OS巊偭偰傞傢偗偠傖側偄偺偱丄梫偼儊僀儞儖乕僾乯偱峴偆昁梫偑偁傝傑偡丅
偦傟傕棤偱嵞峔抸寁嶼偟側偑傜傕曕峴寁嶼偼幚巤偟懕偗傞偺偱丄堦帪揑偵僨乕僞傪擇廳壔偟偰寁嶼偑廔傢偭偨傜堷偒搉偡偲偄偆張棟偑昁梫偱偡丅
幚偼偙偆偄偆偺偼寢峔岲偒偱丄摦偄偨傜婥帩偪椙偄偺偱偡偑丄丄丄僴儅傞偲抧崠偱偡丅
僴儅傜側偄偨傔偵傕僔儈儏儗乕僔儑儞娐嫬丄PC娐嫬偱偠偭偐傝偲僨僶僢僌偟偰偐傜幚婡幚憰偟偨偄偲巚偄傑偡丅
幚婡偵嵹偣傞偵偼偦傟埲奜偵傕栤戣偑偁傝傑偟偨丅
偦傟偼梊尒婍偵傛傝敪惗偡傞椵愊岆嵎偱偡丅僆僼儔僀儞惗惉偱偼椵愊岆嵎偲偄偆傕偺偼柍偄偺偱偡偑丄僆儞儔僀儞惗惉偱偼梊尒婍傪巊偭偰偄傞偨傔椵愊岆嵎偑敪惗偟傑偡丅嫵壢彂偵偁傞傛偆偵惂屼宯傪奼戝宯偵偟偰偄傞偺偱岆嵎偼梷惂偝傟偰偼偄傞偺偱偡偑丄幚嵺偵摦偐偟偰傒傞偲寢峔側岆嵎偑敪惗偟傑偡丅
仈偙傟丄寛傔偮偗偰傑偡偑丄惂屼妛揑偵偦偆側偺偐偳偆偐抦傝傑偣傫丅娫堘偊偰偄偨傜嫵偊偰偔偩偝偄丅幚偼巹偺幚憰儈僗偐傕偟傟側偄偱偡丅
棟憐揑偵偼巭傑偭偨帪偼懍搙偑僛儘側偺偱廳怱揰偼儘儃僢僩偺恀壓偵側傞傛偆側巔惃偵側傞傋偒側偺偱偡偑丄偙偙偵岆嵎偑敪惗偟傑偡丅
3曕曕偄偨偩偗偱丄1儈儕偐傜2儈儕偔傜偄偼岆嵎偑巆偭偰丄師偵曕偒弌偡偲偒偵晄惓摦嶌偺尨場偵側傝傑偡丅
僇乕僽曕峴偡傞偲岆嵎偼奼戝偟丄僐儞僩儘乕儔傪巊偭偰巭傑傜偢偵偆傠偆傠曕偐偣傞偲20儈儕偔傜偄岆嵎偑弌偨傝偟傑偡丅
偦偺傛偆側忬懺偱嵞搙曕偒弌偡偲丄梊尒婍偼僼儔僢僔儏偟偰僼儗僢僔儏側偺偱僼儔僢偲偙偗偦偆偵側傝傑偡丅
扨弮偵慄宍曗惓偟偰妸傜偐偵曗惓偟偰傒偨偺偱偡偑丄偣偭偐偔椡妛寁嶼偟偰婳摴寛傔偰傞偺偵偙偙偱儕僯傾偵岆嵎傪梟偗崬傑偣傞偲偐偐偭偙埆偄側偲巚偭偰傑偟偨丅
側偵傛傝慄宍曗惓偩偲妸傜偐偵偼側傝傑偣傫偱偟偨丅
偙傟偵懳偟偰偼嶐擔傾僀僨傿傾丠傪巚偄晅偒丄弶婜忬懺偱寁夋ZMP偲岆嵎抣傪崌傢偣傞偲偳偆偩傠偆偲丅
寁嶼偟偰傒傞偲傛偝偘偱偡丅丂壓偺僌儔僼偺応崌丄弶婜僆僼僙僢僩偵5儈儕傪擖傟偰偄傑偡丅
慻傒崬傫偱傒偨偺偑偙傟偱偡丅
旤偟偄丅丅
偙偺張棟傪偟側偄応崌偼偙傫側姶偠偱偟偨丅2搙栚偺曕偒弌偟偱丄偪傚偭偲棎傟傞偺偑傢偐傞偲巚偄傑偡丅
偙傟傕尰応懳墳偱偙偺傛偆偵偟傑偟偨偑丄惓偟偄懳張偑偁傞偺偱偁傟偽嫵偊偰偔偩偝偄丅
幚婡偵嵹偣傞偲側傞偲嵶偐側晹暘偱偄傠偄傠偲嶌傝崬傓昁梫偑弌偰偒偰丄偩傫偩傫偲僾儘僌儔儉傕撉傒偵偔偔側偭偰偒傑偟偨丅
偙偺嵞峔抸偺巇慻傒偲偐丄偁偲偐傜撉傕偆偲巚偭偨傜寢峔戝曄偩傠偆側乕偲崱偐傜巚偄傑偡丅
幚偼僆僼儔僀儞曕峴偺帪偵偼儌乕僔儑儞偺宲偓崌傢偣偲偄偆偺傪傗偭偰偄偰丄愙懕偡傞僼儗乕儉偵偍偗傞幙揰枅偺懍搙丄壛懍搙丄儘儃僢僩帺懱偺堏摦懍搙丄曽岦側偳傪堷偒宲偄偱摦偄偰偄傞偲偙傠偐傜偺儌乕僔儑儞傪惗惉偟偰偝偭偲愗傝懼偊傞偲偄偆帠傪傗偭偰傑偟偨丅
僾儘僌儔儉傪彂偄偨杮恖偑丄傗偭偰偄傞帠偼傢偐偭偰偄傞忋偱撉傫偱傕丄偡偱偵夝撉崲擄丅偳偆偟偰偙偆傗偭偰傞偺丠丠側偵傗偭偰傞偺丠丠偭偰売強偽偐傝偱嶲峫偵側傝傑偣傫偱偟偨丅(徫)
僪僉儏儊儞僩傗恾偺椶偼寢峔婥偵偟偰巆偟偰偄傞偮傕傝側偺偵丄傑偩傑偩廫暘側婰榐偵偼側偭偰側偄偭偰偙偲偱偡偹丅
擭枛偱偡丅扨恎晪擟側偺偱婣徣偣偹偽側傝傑偣傫丅
曣娡傕婡懱傕岺嬶傕偡傋偰偙偭偪偵帩偭偰偒偰傞偺偱婣傞偲壗傕偱偒側偄偺偱偳偆偟偨傕偺偐側偲丅
幵偩偐傜曣娡傪帩偭偰婣傞偐側乕偲巚偭偰傑偡丅僨傿僗僾儗僀傪抲偔婘偝偊柍偄偗偳偳偆傗偭偰嶌嬈偟傛偆偐丅丅
偁偲丄偙偆偄偆応柺偑懡偄偺偱偍弌偐偗娐嫬傕峫偊傞昁梫偑偁傝傑偡丅偲傝偁偊偢丄崱偺曣娡傪攦偆慜偵巊偭偰偄偨僲乕僩俹俠偼丄Windows10傪柍彏傾僢僾僨乕僩偱擖傟偨偺偱偡偑丄僆儌僆儌偺忋乮7偺崰傕廫暘偵廳偐偭偨乯丄僄僋僗僾儘乕儔偑偍偐偟偔偰憖嶌偟偰偄傞偲僄僋僗僾儘乕儔偑棊偪傑偡丅乮俷俽偼棊偪側偄偑偟偽傜偔憖嶌晄擻偵側傞乯
僋儕傾僀儞僗僩乕儖偟偨傜巊偊偦偆偩偗偳丄崱峏Win10傪攦偭偰偙偺PC偵擖傟傞偭偰偺傕僶僇傜偟偄偺偱怴偟偄僲乕僩PC乮儕乕僘僫僽儖側傗偮乯傪偝偭偒敪拲偟傑偟偨丅
偙偺僲乕僩偼Linux偱傕擖傟偪傖偍偆偐側乕丅巊傢側偄偩傠偆偗偳偒偭偲偝偔偝偔摦偔偼偢丂(丱仦丱)
偱偼丄崱擭偺峏怴偼偒偭偲偙傟偑嵟屻丅奆條丄椙偄偍擭傪丅棃擭傕傛傠偟偔偍婅偄偟傑偡丅<(_ _)>
偁偗傑偟偰偍傔偱偲偆偛偞偄傑偡丅
怴擭側偺偱夵儁乕僕偟偨偄偲偙傠偩偗偳丄偙側偄偩怴偟偄儁乕僕偵擖偭偨偲偙傠側偺偱懕偗偰彂偔偙偲偵偟傑偡丅
擭枛擭巒偼傗偼傝丄幚壠乮愳嶈偺帺暘偺儅儞僔儑儞乯偵婣傞傋偒側傫偩傠偆偗偳丄扨恎晪擟偺偨傔偵堦愗崌嵿傪嶳棞偵帩偭偰偒偰偄傞傕偺偩偐傜丄奐敪娐嫬偼偍傠偐丄拝傞暈偝偊傕帩偭偰婣傜側偗傟偽偄偗側偄丅
偄偔傜幵偱偺堏摦偲偼偄偊丄壸暔偑懡偔側傞偺偼弨旛傕曅晅偗傕戝曄側偺偩偑丄傗偭傁婣傜側偒傖僟儊偩傛偹丅偲偄偆偙偲偱婣傞偙偲偵丅婣偭偪傖偆偲偩傜偩傜偲擭枛擭巒偺偔偩傜側偄僥儗價傪尒懕偗傞偙偲偵側傞偺偱乮偦傟偼偦傟偱椙偄偺偩偑乯偙偙偼傂偲偮僨僗僋僩僢僾俹俠傪帩偭偰婣偭偰幚壠偱奐敪嶌嬈傪偟傛偆偲丅
偙側偄偩GoSimulation忋偺僾儘僌儔儉傪幚婡幚憰傪憐掕偟偨宍偵彂偒姺偊偰傗偭偲摦偄偨偺偩偑丄偳偆傕偦偺屻摦偒偑偍偐偟偄婥偑偡傞丅丂側傫偩偐幚憰傪曄偊傞慜偲屻偲偱偼晄埨掕側働乕僗偑懡偔側偭偨傛偆側婥偑偡傞丅偄傗丄晄埨掕偵側偭偰傞丅
偙傟偼偮傑傝僶僌偑擖傝崬傫偩傢偗偱丄傗偭偲摦偄偨偺偵僶僌偑偁傞偲偼偙傟偼傕偆傔傫偳偔偝偄帠偵側傞偲寛傑偭偰偄傞偺偱擭枛擭巒偺傑偲傔偰帪娫偑庢傟傞帪偵傗傞偟偐側偄偲偄偆帠偱偡丅
僨傿乕僾儔乕僯儞僌傎偳偠傖側偄偗偳丄懡師尦曄悢傪巊偭偨惂屼儌僨儖偩偲嵶偐側悢抣嵎偩偲曗惓偟偪傖偭偰偁偐傜偝傑偵偍偐偟偔側傜側偔偰僶僌偑尒偊偵偔偄丅乮偺偱偼側偄偐偲巚偄傑偡丅側傫偣弶傔偰側偺偱丅丅乯
崱夞傕戝懱偼偆傑偔曕偗傞偺偵偨傑偵晄埨掕偵側偭偨傝偙偗偨傝偡傞丅暔棟僔儈儏儗乕僞忋偩偲愨懳埨掕曕峴偡傞傢偗偠傖側偔偰備傜偓側偺偐僇僆僗側偺偐傢偐傜側偄偗偳昁偢摨偠摦嶌傪偡傞傢偗偠傖側偔偰枅夞堘偭偨摦偒傪偡傞偺偱側傫偐偺搒崌偱晄埨掕偩偭偨傝傕偁傝摼傑偡丅
側偺偱丄晄埨掕側偺偩偗偳婥偺偣偄丠偲傕姶偠傑偡丅偄傗丄婥偺偣偄偱偁偭偰梸偟偄偲巚偭偰傞偺偐傕丅僨僶僢僌傔傫偳偆偩偐傜丅丅
偙傟偑幚婡偩偭偨傜僾儘僌儔儉傛傝儊僇傪媈偭偰僱僕掲傔偟偰傞偲偙偱偡丅
僶僌偺懚嵼傪柧妋偵偡傞偨傔偵偼傗偼傝僨乕僞庢傝偑昁梫偱偡丅
曕峴宲懕偺偨傔偵丄寁夋ZMP傪搑拞廋惓偟偰梊尒僨乕僞傪嵞峔抸偟偰偄傞傢偗偱偡偑丄捈恑傪宲懕偡傞応崌傕偨偲偊偽乽3曕曕偄偰巭傑傞乿偲偄偆寁夋傪廋惓偟偰搑拞偐傜乽偙偙偐傜偝傜偵5曕曕偄偰巭傑傞乿偲偄偆晽偵曄峏偡傞傢偗偱偡丅
嵟弶偺寁夋偑3曕偩偲丄偡偖偵掆巭僼僃乕僘偺摦嶌偑梊尒僨乕僞偵擖傞偺偱傗傗偙偟偄偱偡偑丄乽5曕曕偄偰巭傑傞乿偲偄偆寁夋偵偡傟偽丄梊尒僨乕僞偼曕偄偰偄傞晹暘偩偗偺忬懺偲偄偆偺偑彮偟懕偒傑偡丅偙偙偵乽偙偙偐傜偝傜偵5曕曕偄偰巭傑傞乿偲偡傟偽丄尦乆偺梊尒僨乕僞偲嵞峔抸偟偨梊尒僨乕僞偵嵎偑側偔側傞偲偄偆僞僀儈儞僌偑嶌傟傑偡丅
偦傟傪傗偭偨偺偑偙偺僌儔僼
亂傑偭偡偖曕偄偨偩偗偺僌儔僼亃
亂捈恑傪宲懕偟偨応崌偺僌儔僼亃
偁傑傝嵎偑柍偄傛偆偵尒偊傑偡偑丄300儈儕恑傫偩曈傝偺嵍塃怳暆偑彮偟戝偒偔側偭偰偄傑偡丅
慜屻摦嶌傕傎傏捈慄偺偼偢偑丄300儈儕偺偁偨傝偵彮偟傂偢傒偑偁傝傑偡丅
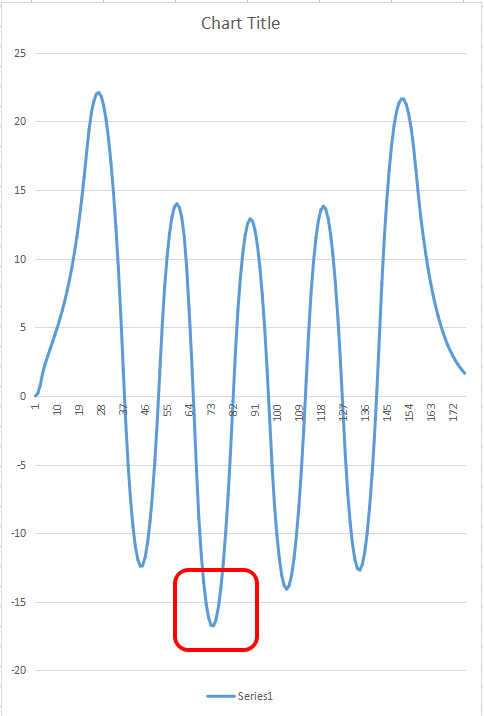
僔儈儏儗乕僞夋柺偱偼偙偺怳暆嵎偺偍偐偘偱儘儃僢僩偼彮偟傛傠傔偒傑偟偨丅 偙傟偔傜偄偺嵎偱傛傠傔偄偪傖偆傫偱偡偹丅2懌曕峴偑擄偟偄偼偢偱偡丅
偆傑偔摦偄偰偄偨傜偙偺傛偆側嵎偼偱偒側偄偼偢側偺偵嵎偑偱偒偰偟傑偭偰偄傞偲偄偆偙偲偼傗偼傝僶僌偑偁傞傛偆偱偡丅
僶僌偑妋怣偱偒偨偺偱杮奿揑偵僨僶僢僌偺奐巒偱偡丅
僐乕僪儗價儏乕偟偰傕廤拞椡偑懕偐側偄偺偱傗偼傝僨乕僞傪庢偭偰僶僌傪椶悇偡傞偲偄偆曽朄偱峴偒傑偡丅
傑偢丄僼儗乕儉偵敳偗傗廳暋偑側偄偐傪挷傋傑偟偨偑丄偳偆傗傜偦傟偼戝忎晇偦偆丅
師偵堷偒宲偓帪偺梊尒婍偺僨乕僞傪斾妑偡傞偲丄傕偆慡慠堘偄傑偡丅嵟弶偐傜偙傟傪尒傟偽僶僌偺懚嵼偼妋怣偱偒偨傢偗偱偡偑丅
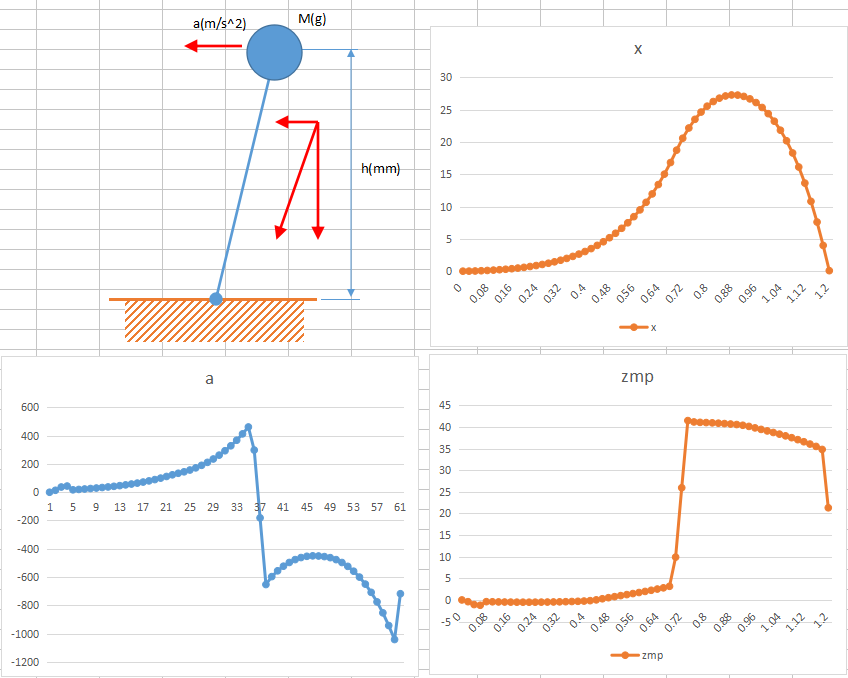
偦偟偰丄梊尒婍偺僨乕僞傪尒偨偭偰側傫偵傕傢偐傜傫偺偱丄栚昗ZMP偲丄僆儞儔僀儞惗惉婍偺弌椡偱摦偄偨帪偺懡幙揰儌僨儖傪巊偭偨ZMP偺嵎乮偮傑傝丄梊尒僨乕僞偺擖椡抣乯偑嵞峔抸慜屻偱嵎偑偁傞偙偲傪敪尒偟傑偟偨丅
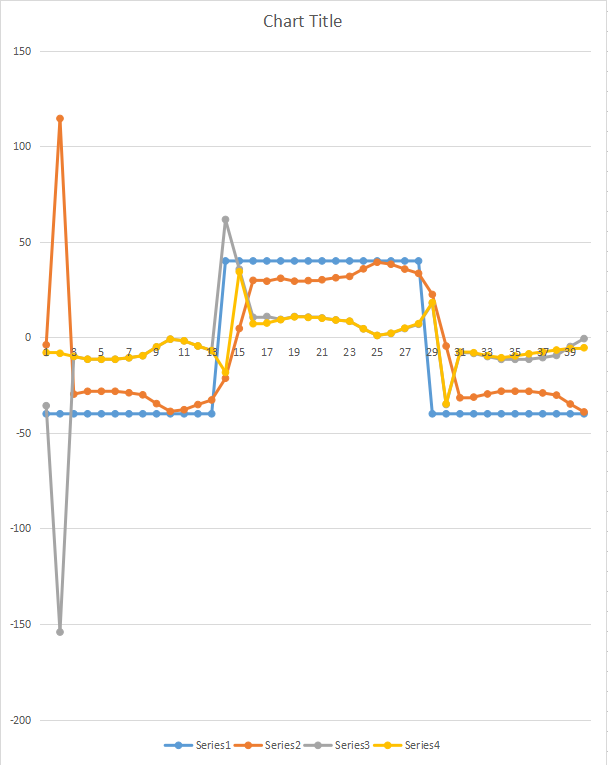
3杮栚偲4杮栚偺僌儔僼傪尒傞偺偱偡偑丄偍偐偟偄偲偙傠偑2揰丅
傑偢丄僌儔僼偺嵟弶偺2僼儗乕儉偱嵎暘偑偁傞丅
師偵ZMP偑曄壔偡傞億僀儞僩偱嵎暘偑偁傞丅偨偩偟丄偙偪傜偼1僼儗乕儉偩偗丅
1僼儗乕儉偢傟偑偁傞偺偐側偲巚偭偨偗偳丄嵟弶偼2僼儗乕儉偢傟偑偁傞偟丠丠丠
嵟弶偺2僼儗乕儉偢傟傞偭偰偺偼懍搙丄壛懍搙僨乕僞偑堷偒宲偘偰側偄偭傐偄偟丄曄壔揰偱1僼儗乕儉偢傟傞偭偰偺偼斾妑偡傞嵺偵1僼儗乕儉偢傟偰傞偭傐偄丅
寢嬊丄僶僌偼2揰偁傝傑偟偨丅
傑偢丄偡偭偐傝朰傟偰偄傑偟偨偑丄寁夋ZMP偲懡幙揰儌僨儖偵傛傞ZMP傪斾妑偡傞嵺丄摨偠僼儗乕儉偱斾妑偡傞偲嵎暘偑戝偒偔側傝偡偓傞偺偱斾妑偼傂偲偮慜偺寁夋ZMP偲斾妑偟偰偄偨揰偱偡丅
壛懍搙傪埖偆応崌丄3揰偺埵抲忣曬偑昁梫偱偡丅
a = (p3 - p2) - (p2 - p1) = p3 - 2 * p2 + p1
寁夋ZMP偺傛偆偵抣偑寖曄偡傞応崌丄曄壔偺寢壥偑2僼儗乕儉尰傟傑偡丅偦偙偱丄f1乣f3偺3僼儗乕儉偱媮傔傜傟傞壛懍搙偼拞娫揰f2偺壛懍搙偲偟偰埖偆偙偲偵偟傑偟偨丅
偦偺偨傔丄嵎暘寁嶼傪偡傞嵺丄乽慜偺僼儗乕儉乿傪屇傃弌偟偰偄偨偺偱偡偑丄幚婡幚憰傪栚巜偟偨幚憰偱偼丄寁夋ZMP楍傪愙懕偣偢偵寁嶼偟偰偄偨偨傔丄寁夋曄峏揰偱乽慜偺僼儗乕儉乿偑懚嵼偟側偄揰偑偁傝傑偟偨丅
塣偺埆偄偙偲偵愭摢僼儗乕儉偺張棟乮偮傑傝慜偺僼儗乕儉偑懚嵼偟側偄応崌乯傕婰嵹偟偰偄偨偨傔丄堦尒偪傖傫偲摦偄偰偟傑偭偰偄偨傢偗偱偡丅
傕偆堦偮偺僶僌偼丄懡幙揰儌僨儖忋偺僶僌偱偟偨丅
懡幙揰儌僨儖偱ZMP傪寁嶼偡傞偨傔丄夁嫀2僼儗乕儉偺埵抲僨乕僞傪曐娗偟偰偄傞偺偱偡偑丄儕僙僢僩巜帵僼儔僌偑棫偭偰偄傞応崌偼夁嫀僨乕僞傪僋儕傾偟偰張棟偡傞婰弎偑偁傝丄嵞峔抸帪偵偦傟偑摥偄偰偟傑偭偰偄偨偲偄偆偙偲偱偡丅
偦偺偨傔丄偙偺僶僌偼僾儘僌儔儉摦嶌奐巒偛嵟弶偺嵞峔抸帪偩偗敪惗偟傑偡丅2搙栚偺嵞峔抸偱偼儕僙僢僩巜帵僼儔僌偼棫偭偰偄側偄偨傔丄惓忢偵摦偒傑偡丅
廋惓偟偨寢壥丄嵞峔抸慜屻偱弌椡偑堦抳偟傑偟偨丅
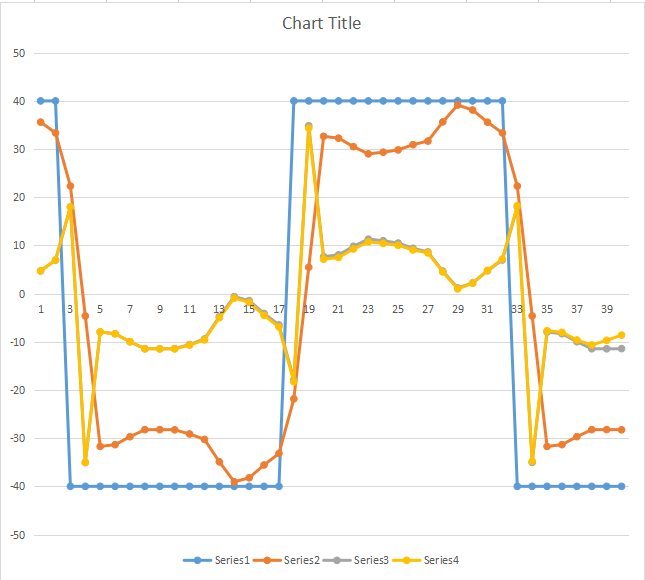
姰慡偵堦抳偟偰偄側偄偺偱傑偩壗偐塀傟偰偄傞偺偐傕抦傟側偄偱偡偑丄戝偒側僶僌偼庢傟傑偟偨丅偲傝偁偊偢偙傟偱愭偵恑傒傑偡丅
偲偆偲偆摦椡妛僼傿儖僞乕傪帩偭偨僆儞儔僀儞曕梕惗惉僾儘僌儔儉傪幚婡偵幚憰偡傞帪偑偒傑偟偨丅
偝偰億乕僥傿儞僌丅
崱夞偼PC娐嫬偱僾儘僌儔儉傪彂偄偰偄傞帪傕丄幚婡偵嵹偣傞帠傪峫椂偟偰彂偄偰偄偨偺偱斾妑揑娙扨偵幚憰偱偒偪傖偭偨傝偟偰丄偲偐怱偺墱掙偱偼峫偊偰偄傑偟偨丅
偲傝偁偊偢丄幙揰儌僨儖偲偐ZMP曕峴惗惉晹偲偐偦偺懠偺峴楍寁嶼偲偐丄IK丄DK寁嶼偲偐傪幚婡僾儘僌儔儉偵嵹偣傑偡丅
偱丄尰嵼偺儊僀儞儖乕僠儞偺傑傑僐儞僷僀儖偟偨偲偙傠丄廳戝側栤戣傪巚偄弌偟傑偟偨丅
乽偁丄malloc巊偊側偄傫偩偭偨丅乿
STM32偺娐嫬偩偲儊儌儕娗棟偑柍偄偺偱malloc()偲偐丄printf()偲偐丄atof()偲偐偑巊偊側偄傫偱偡偹丅
偙傟傜偼娭悢撪偱晄掕挿偺儊儌儕乕傪巊偆偺偱偦偺応偱儊儌儕乕傪妋曐偟偰張棟傪偡傞宯偺娭悢偱偡丅
偦偺懠丄僼傽僀儖僔僗僥儉傗昗弨弌椡丄昗弨擖椡傪巊偆娭悢傕巊偊傑偣傫丅
偮傑傝OS偺僔僗僥儉僐乕儖偵棅偭偰偄傞晹暘偑僟儊側傢偗偱偡丅OS柍偄傢偗偱偡偐傜摉慠偱偡丅
偱傕丄彫宆偺慻傒崬傒僔僗僥儉側傜OS偑柍偄応崌傕懡偄傢偗偱丄偦偺偨傔偵Newlib偲偄偆僷僢働乕僕丠偑偁偭偰偦傟傪偒偪傫偲摫擖偡傟偽僔僗僥儉僐乕儖偺戙懼偊娭悢傪梡堄偡傞偙偲偑偱偒傑偡丅
偦傟傪傗傜側偄偲幚婡幚憰偳偙傠偠傖側偐偭偨丅
尦乆帺棩宆儘儃僢僩傪嶌傝偨偔偰儘儃僢僩摴偵擖偭偨偺偱丄巊偭偰偒偨僐儞僩儘乕儔偼寢峔僿價乕側傫偱偡偹丅
儘儃僢僩僉僢僩偼Speecys偐傜偱偟偨丅
偙偄偮偺僐儞僩儘乕儔偼妋偐PowerPC宯偺CPU偱BSD-UNIX偑嵹偭偰偰UNIX僾儘僌儔儉偱摦偐偟偰偄傑偟偨丅
師偵巊偭偨偺偼SEMB1200A偭偰傗偮偱偙偄偮偼幚偼OS側偟偩偭偨傫偱偡偗偳丄FPU愊傫偱偰RAM偼512k僶僀僩愊傫偱傑偟偨丅
採嫙偝傟偰偨儔僀僽儔儕偼丄懡暘Newlib偱偩偲巚偆偗偳malloc()巊偊偰傑偟偨丅丂妋偐奐敪尵岅偼C++巊偭偰偨傛偆側妎偊偑丅偁丄C++偼Speecys偩偗偐丅
ZMP婯斖偺僆僼儔僀儞曕梕惗惉乿傪傗偭偰偨偺偼偙偄偮傜偱偱偡丅傑偲傕偵曕偄偨偺偼SEMB偐傜偱偡偹丅
曕偐側偐偭偨偺偼儊僇偺栤戣偱Speecys偺僐儞僩儘乕儔偼偄偄搝偱偟偨丅乮傑偩惗偒偰傑偡偑乯
Go Simulation忋偱摦偐偟偰偄偨摦椡妛僼傿儖僞乕偺僾儘僌儔儉偼偙傟傜偺僐乕僪傪寢峔側検傪棳梡偟偰嶌偭偰偄傑偡丅
偦偆偄偆攚宨傕偁偭偰摦椡妛僼傿儖僞乕偺幚憰偵偼malloc()傪懡梡偟偰偄傑偡丅
傑偢丄幙揰儌僨儖偱偼僲乕僪枅偵愙懕揰偑帺桼悢帩偰傞傛偆偵偟偰偄傑偡丅
偙偺帺桼悢偲偄偆偺偼儕僗僩偱昞尰偟偰偄傑偡丅
偮偄偱偵庤懌傗摲懱傕儕僗僩偵側偭偰偄傑偡丅
偨偲偊偽暔傪帩偭偨応崌丄榬偺愭抂偵帩偭偨儌僲傪怴偨側幙揰偲偟偰儘儃僢僩杮懱偲堦弿偵廳怱寁嶼偑偱偒傑偡丅
暔傪帩偭偨忬懺偱曕偐偣傞偲帩偭偨暔偺忣曬乮幙揰傗廳検傪偳偆寛傔傞偐偑暿搑昁梫偩偗偳乯傪峫椂偟偰曕偔偙偲偑偱偒傑偡丅
懡暘丄捈棫偟偰帩偭偰偰傕摦椡妛僼傿儖僞乕傪摥偐偣傞偲廳怱揰傪曗惓偟偰彮偟崢傪堷偄偰曕偔丄傒偨偄偵側傝傑偡丅
僆儞儔僀儞惗惉偺栚昗ZMP楍傕儕僗僩偱偡丅僆僼儔僀儞偺帪偼2杮偺儕僗僩傪帩偭偰偄偰丄忋庤偵愗傝懼偊偰丄棤偱怴偨偵惗惉偟偰丄偲偄偆偙偲傪傗偭偰傑偟偨偑丄崱夞偼1杮偺儕僗僩傪宲偓懌偟偰巊偭偰偄傑偡丅惓妋偵偼棤偱嶌偭偨宲偓懌偟晹暘傪惓婯儕僗僩偵宲偓懌偡偲偄偆偙偲傪傗偭偰傑偡丅巊偄廔傢偭偨僨乕僞晹暘偺儊儌儕乕偼偳傫偳傫偲夝曻偟偰偄偒傑偡丅
梊尒晹暘傕儕僗僩偱偡丅婎杮揑偵偼栚昗ZMP楍偲摨偠巇慻傒偱丄幙揰儌僨儖偐傜寁嶼偟偨寁嶼ZMP偲僆儞儔僀儞惗惉偱寁嶼偟偨扨怳巕儌僨儖偺寁嶼ZMP偺嵎偺楍傪奿擺偟偰偄傑偡丅
栚昗ZMP楍偑曄峏偵側偭偰丄梊尒僨乕僞傪嵞峔抸偡傞偲偒偼尰忬僨乕僞偱儘儃僢僩傪摦偐偟偮偮丄棤偱嵎偟懼偊僨乕僞傪峔抸偟傑偡偑偙偙偱傕怴偨偵儕僗僩傪嶌傝丄愗傝懼偊偺僞僀儈儞僌偱嵎偟懼偊傑偡丅
傕偆偁偪偙偪偱malloc()巊偄傑偔傝偱偡丅malloc()偑側偗傟偽惗偒偰偄偗傑偣傫丅
偲偄偆偙偲偱malloc()傪巊偊傞傛偆偵偡傞偨傔偺曌嫮偱偡丅
僼僃僀僗僽僢僋偱偮傇傗偄偨偲偙傠丄僥僋僲儘乕僪偺悪塝偝傫偐傜乽Coron+偺儔僀僽儔儕偼malloc()懳墳偟偰偄傞乿偲偄偆忣曬傪偄偨偩偒傑偟偨丅
幚偼STM32帠巒傔偼Coron偱偟偰丄僔僌儅傕弶婜偺崰偼Coron偱摦偐偟偰偄傑偟偨丅丂崱偼STBee傪巊偭偰偄傞偺偱偡偑丄Coron偺奐敪娐嫬偺堦晹傪崱傕巊偭偰偄傑偡丅
幚偼偙偺娫偵偪傚偭偲幐攕偑丅
MentorGraphics偐傜棊偲偟偰偒偨僐儞僷僀儔丒儔僀僽儔儕偼儂儞僩偵malloc()懳墳偟偰偄側偄偺偐側丠偲巚偭偰僔儞儃儖僥乕僽儖傪挷傋偰傒傑偟偨丅
$ nm libc.a | grep sbrk
U __malloc_sbrk_base
U _sbrk_r
0000002c B __malloc_max_sbrked_mem
00000408 D __malloc_sbrk_base
U _sbrk_r
lib_a-sbrkr.o:
U _sbrk
00000001 T _sbrk_r
lib_a-syssbrk.o:
U _sbrk_r
00000001 T sbrk
偁傟丠懳墳偟偰傞傗傫丅偭偰巚偭偰偟傑偄傑偟偨丅
T偭偰偺偑幚懱偑偁傞僔儞儃儖偱丄U偭偰偺偼屇傃弌偟愭僔儞儃儖偱幚懱偑側偄丅
嵟屻偵T sbrk丂偭偰偁傞偺偱幚懱偑偁傞偲傒偰偟傑偭偨偺偩偑丄傛偔尒傞偲傾儞僟乕僶乕偑側偄丅偙傟偼撪晹娭悢_sbrk()偲偼暿偺儐乕僓乕娭悢sbrk()側傫偱偡偹丅sbrk()偼_sbrk()偑側偔偰傕摦偔傢偗偩丅
偙偺姩堘偄偵婥偯偐偢偵偟偽傜偔偁偁偱傕側偄偙偆偱傕側偄偲婃挘偭偰偟傑偄傑偟偨丅
偱丄Coron+偱摦偔偺傪妋擣偟偰偐傜丄偭偰忔傝偱娐嫬傪僟僂儞儘乕僪偟偰丄儔僀僽儔儕傪僐僺乕偟偰摦偐偟偰傒偨偺偱偡偑丄摦偐側偄丅偁傟丠摦偐側偄傗傫丅僔儞儃儖僥乕僽儖挷傋偨傜偝偭偒偲摨偠傛偆側弌椡偵丅
懳墳偟偰偄傞偼偢偺儔僀僽儔儕側傢偗偩偐傜丄傗偭傁曌嫮偟側偒傖偩傔偩側乕偲偄偆偙偲偱Coron+偺儔僀僽儔儕偼墶偵抲偄偰偍偄偰曌嫮偡傞偙偲偵丅
怓乆挷傋偨寢壥丄OS側偟偺慻傒崬傒宯偱丄僔僗僥儉僐乕儖宯偺庴偗搉偟傪偝偣傞偵偼丄
1丏syscall.c傪慻傒崬傓丅丂丂偳偙偐傜偐偙偄偮傪扵偟偰偒偰儕儞僋偡傞丅
2丏libnosys.a傪儕儞僋偡傞丅
3. -specs=nosys.specs 傪僐儞僷僀儖僆僾僔儑儞偵捛壛偟偰僐儞僷僀儖偡傞丅
曈傝偑嬶懱揑側張棟偲偟偰晜忋偟傑偟偨丅
寢嬊偼忋婰偺張棟偱丄_sbrk(),_read(),_write(),_seek(),_stat()偲偐偺娭悢偑捛壛偝偣傞偲偄偆偙偲偱偡丅
3.偼丄幚偼2丏偲傎傏堦弿偱偡丅specs僼傽僀儖偺拞恎偼儔僀僽儔儕偵libnosys.a傪捛壛偡傞張棟偵側偭偰傑偡丅
1丏偺僼傽僀儖偺拞恎偼忋婰偺僔僗僥儉僐乕儖宯娭悢偺幚懱偑婰弎偝傟偰偄傑偡丅
偙傟偱make偼捠傞傛偆偵側傞偼偢偱偡丅
東偭偰MentorGraphics偲Coron+偺儔僀僽儔儕傪尒偰傒傞偲丄Coron+偵偼libnosys.a傕nosys.spec傕採嫙偝傟偰偄傑偡丅
MentorGraphics偵偼柍偄偺偱傗偼傝懳墳偝傟偰偄側偄傜偟偄丅
sbrk()偼僸乕僾偲屇偽傟傞枹巊梡偺儊儌儕乕嬻娫偐傜昁梫偵墳偠偰儊儌儕乕傪妱傝摉偰偰偄偒傑偡丅
偦偺僸乕僾偑偳偙偵偁傞偐傪嫵偊偰傗傞昁梫偑偁傞傜偟偔丄偙偺偨傔偵奜晹曄悢_end傪嶲徠偡傞傜偟偄偱偡丅
儕儞僇僗僋儕僾僩偱偙偺愝掕傪傗傜側偗傟偽側傜側偄傜偟偄丅
儅僀僐儞傪怗傝巒傔偨偙傠偼丄Z80偺僀儞僗僩儔僋僔儑儞僙僢僩傪慡晹婰壇偟偰偰丄婡夿岅傪僜儔偱撉傔偨偲偄偆帪婜傕偁傝傑偡偑丄儅僀僐儞偑庯枴偩偭偨偙傠偐傜UNIX丄儘儃僢僩偲堏峴偡傞側偐偱丄僾儘僌儔儉偼婰弎惈偑廳梫丅傔傫偳偔偝偄帠偵偼嬤偯偐側偄偲偄偆曽恓偱恑傔偰偒偨偺偱丄娐嫬峔抸偲偐傕偱偒傞偩偗恖偺懌愓傪偨偳傞傛偆偵偟偰嬯楯傪攔彍偟偰偒傑偟偨丅
側偺偱丄偄傑傑偱儕儞僇僗僋儕僾僩傪怗傞傛偆側偲偙傠偵摜傒崬傑側偄偱傗偭偰偒傑偟偨偑丄偲偆偲偆偦偺拞傪尒傞擔偑棃偨傛偆偱偡丅
儅僀僐儞偺悽奅偱偼桳柤恖偱偁傠偆乽偹傓偄偝傫乿偺僽儘僌丄乽偹傓偄偝傫偺僽儘僌乿偼忣曬偺曮屔偱偡丅彂偄偰偄傞偙偲偑棟夝偱偒側偄偔傜偄徻偟偄偱偡丅偙偙偵偙偺栤戣偑彮偟嵹偭偰偄偰偦傟傪懌偑偐傝偵儕儞僇僗僋儕僾僩偺婰弎暥朄側偳傪棟夝偟偰偄偒傑偡丅
掕媊偝傟偨曄悢椞堟 .bss僙僋僔儑儞偺屻傠偵_sbrk偑嶲徠偡傞_end偑愝掕偝傟傞傋偒丄偲偄偆偙偲側偺偱Coron偺僗僋儕僾僩傗偹傓偄偝傫忣曬側偳傪崌傢偣偰偙傫側晽偵偟傑偟偨丅
_Min_Heap_Size = 0x1000;
.bss :
{
. = ALIGN(4);
_sbss = .;
*(.bss)
*(COMMON)
. = ALIGN(4);
_ebss = . ;
} >RAM
.heap :
{
PROVIDE ( end = _ebss );
PROVIDE ( _end = _ebss );
. = . + _Min_Heap_Size;
. = ALIGN(4);
} >RAM
ALIGN(4)偼4僶僀僩扨埵偱抂悢傪旘偽偡
*(.bss)偭偰偺偼僆僽僕僃僋僩撪偺掕媊嵪傒曄悢(側傫偪傖傜.bss)偺偙偲偱丄偙偙偵攝抲偝傟傞
偱丄.heap僙僋僔儑儞偺摢偵_end傪愝掕偟丄.bss僙僋僔儑儞偺廔傢傝_ebss傪戙擖偟偰偄傑偡丅
僸乕僾偺僒僀僘偭偰偺偑昁梫側偺偐偳偆偐傢偐偭偰側偄偱偡偑丄_Min_Heap_Size偲偟偰0x1000僶僀僩傪愝掕偟偰偄傑偡丅
乽end乿偲乽_end乿偑偁傞偺偼張棟宯偱偳偪傜傕偁傞偺偐側丠偲丅
偙傟偱make偡傞偲
stbee-led.elf :
section size addr
.isr_vector 484 134230016
.flashtext 0 134230500
.text 16572 134230500
.data 2136 536870912
.bss 732 536873048
.heap 4096 536873780
._usrstack 256 536877876
.stab 58452 0
.stabstr 88228 0
.comment 110 0
.ARM.attributes 47 0
.debug_aranges 664 0
.debug_info 57594 0
.debug_abbrev 11799 0
.debug_line 10474 0
.debug_frame 2348 0
.debug_str 5179 0
.debug_loc 12924 0
.debug_ranges 1128 0
Total 273223
偺傛偆偵側傝丄僸乕僾偑妋曐偝傟偰偄傞偺偑傢偐傝傑偡丅丂偱傕偙傟偱偄偄偺偐傢偐傝傑偣傫偑丅
僗僞僢僋(._usrstack)偑0x0100僶僀僩愝掕偝傟偰傞偗偳丄偙偺屻傠偵僸乕僾傪帩偭偰偄偐側偔偰偄偄偺偐側丠
sbrk()偱梕検憹傗偣傞偭偰僀儊乕僕偩偗偳丄僗僞僢僋僄儕傾傪嫴傫偱僄儕傾傪妋曐偡傞偺偐側丠
偲偐怓乆媈栤偩傜偗偱偡丅
偝偰丄僐儞僷僀儖偱偒偨偐傜偄偄偐偲偄偆偲幚偼慡慠偩傔偱丄摦偒傑偣傫丅
幚偼MentorGraphics偱娐嫬傪嶌偭偰摦偔偺傪妋擣偟偰偄偨傫偩偗偳丄make clean偱偼STM32偺愱梡儔僀僽儔儕libcm3.a偲偐儁儕僼僃儔儖儔僀僽儔儕libstd.a偼僋儕傾偝傟傑偣傫丅
MentorGraphics偺娐嫬偵偟偨偺偼崱偺僨僗僋僩僢僾偺曣娡傪攦偭偰偐傜偱丄偦傟傑偱偼傕偭偲屆偄僶乕僕儑儞偺gcc僐儞僷僀儔傪巊偭偰傑偟偨丅
偦偺帪偵峔抸偟偨儔僀僽儔儕偑偦偺傑傑巊偊偰偄偨偺偱傑偀偄偄傗偲丅
偱傕丄慡晹嵞峔抸偟偨曽偑偄傠偄傠晄惍崌偑弌側偔偰偄偄傫偠傖側偄偺丠偲巚偭偰make distclean偟偰儔僀僽儔儕偐傜嵞峔抸偟偰傒偨傜丄core_cm3.c偺僐儞僷僀儖偱傾僙儞僽儔偑僄儔乕弌偟偰偟傑偄傑偡丅
偙傟偼傕偆僨僶僢僌懳徾偠傖側偔偰僐儞僷僀儔偺栤戣偩偐傜傕偆偄偄傗偲巚偭偰makedistclean慜偺儔僀僽儔儕傪暅妶偝偣偰偄傑偟偨丅
偙側偄偩Launchpad偐傜棊偲偟偰偒偨娐嫬偼M4偵傕M4偺FPU偵傕懳墳偟偰偄傞偺偱偙傟偼偄偄両偲巚偭偰摦偐偟偰傒偨偺偱偡偑丄偙偺丄廬棃偺儔僀僽儔儕偲儕儞僋偡傞曽朄偱偼偆偛偒傑偣傫丅乮屻弎丄儕儞僋僗偡傞儔僀僽儔儕偑娫堘偊偰偄偨乯
儔僀僽儔儕偺僶乕僕儑儞偼4.8.1丄Launchpad偼5.8.3丄偒偭偲偙偺僶乕僕儑儞堘偄偑栤戣側偺偩傠偆偲巚偭偰偄傑偟偨丅
栠偭偰丄僐儞僷僀儖偱偒偨傕偺偼乽廬棃偺libcm3.a乿亄乽Coron+儔僀僽儔儕乿亄MentorGraphics僐儞僷僀儔偱偡丅
偆傑偤偙偤偱偡丅偲傝偁偊偢僐儞僷僀儔傕Coron偵偟偰傒偰傕寢壥偼摨偠丅
偙傟偼傕偆丄Coron偱慡晹偦傠偊傞偟偐側偄丅libcm3.a傪Coron斉偱峔抸偡傞偟偐側偄側偲偄偆偙偲偱挷傋偰傒傞帠偵丅
偪傚偭偲挷傋偨傜乽偹傓偄偝傫偺僽儘僌乿偵MentorGraphics偩偲堷偭偐偐傞偲偄偆榖偑弌偰傑偟偰丄偢偽傝偙偺栤戣偑庢傝忋偘傜傟偰傑偟偨丅
夝寛嶔偲偟偰偼乽僴乕僪僐乕僥傿儞僌偟偰夞旔乿偑偹傓偄偝傫偺摎偩偭偨偺偱偡偑丄偦偺屻偺幆幰偐傜偺僐儊儞僩偱傾僙儞僽儔傪惂屼偟偰偒傟偄偵夝寛偡傞嶔偑偁傞偲丅偲偙傠偑偹傓偄偝傫偼偦偺夝寛嶔傪儕儞僋偱帵偟偰偄偰僽儘僌杮暥偵偼彂偄偰側偄偺偱偡両
儕儞僋愭偼乽傊側傊側僴僀僇乕乿偲偐偄偆嶳搊傝偺僽儘僌偵側偭偰偰傾僙儞僽儔乕偲偼墢墦偦偆側偲偙傠偵旘傃傑偡丅
巇曽偑側偄偺偱崱搙偼僀儞儔僀儞傾僙儞僽儔偺曌嫮偱偡丅乽憗婜攋夡僆儁儔儞僪乿偲偄偆偺傪僉乕儚乕僪偵扵偟夞傝丄傗偭偲尒偮偗傑偟偨丅
__ASM volatile ("strexb %0, %2, [%1]" : "=r" (result) : "r" (addr), "r" (value) );
丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂伀
__ASM volatile ("strexb %0, %2, [%1]" : "=&r" (result) : "r" (addr), "r" (value) );
__ASM volatile ("strexh %0, %2, [%1]" : "=r" (result) : "r" (addr), "r" (value) );
丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂伀
__ASM volatile ("strexh %0, %2, [%1]" : "=&r" (result) : "r" (addr), "r" (value) );
偙偺2偐強偱偡丅傢偐偭偰傞恖偵偼悢昩偱廔傢傞帠傪壗帪娫傕挷傋偨傝帋峴嶖岆偡傞偺偭偰儂儞僩偵偄傗偵側傝傑偡偹丅
偙傟偱丄MentorGraphics 偱傕 Coron+ 偱傕make偼捠傞傛偆偵側傝傑偟偨丅弛疾
make偼捠傝傑偟偨偑丄偪傖傫偲摦偔偺偼MentorGraphics斉偩偗丅Coron+傕Lunchpad傕傄偔傝偲傕摦偒傑偣傫丅
尰忬偺儔儉僟偺僾儘僌儔儉傕偄傠傫側儁儕僼僃儔儖傪怗偭偰怓乆傗偭偰傞偺偱壗偑尨場偐傢偐傜側偄偺偱丄stroberry-linux偐傜STBee-mini偺僒儞僾儖僾儘僌儔儉LED偑僠僇僠僇偡傞偩偗偺僾儘僌儔儉傪憱傜偣偰傒傞偲丄Coron+偺僐儞僷僀儔偱摦偒傑偡丅
偙傟偭偰儁儕僼僃儔儖儔僀僽儔儕偲CM3儔僀僽儔儕偟偐儕儞僋偟偰側偄偺偱偡丅
偳偆傗傜GCC偺儔僀僽儔儕孮偑栤戣傜偟偄丅MentorGraphics斉偱偼thumb2丄偦傟埲奜偱偼thumb偭偰偺偟偐側偄偺偱thumb偺僨傿儗僋僩儕乕偵擖偭偰偄傞儔僀僽儔儕傪儕儞僋偟偰偄傞偺偱偡偑丄偙傟偑栤戣壔丠2偠傖側偄偐傜僟儊側偺丠
戝懱thumb偭偰壗丠
偲巚偭偰寉偔挷傋偨傜丄偳偆傗傜 thumb偭偰偺偼16價僢僩柦椷偲偐32價僢僩柦椷偲偐偱僐乕僪岠棪壔偺偨傔偺奼挘僀儞僗僩儔僋僔儑儞僙僢僩傜偟偄偱偡丅
僐儞僷僀儖傕thumb偭偰僆僾僔儑儞偮偗偰傞偟丄偙傟偱偄偄傛側乕偲巚偄側偑傜丄柍報偺儔僀僽儔儕傪儕儞僋偟偰傒偨傝偟偰傕摦偐側偄丅
偁偲偼armv7-m偲偐armv7e-m偲偐偺忋埵CPU乮偲巚偭偰偄偨乯偺儔僀僽儔儕偟偐側偄丅
峏偵僱僢僩偱忣曬傪扵偟偰偄傞偲丄乽偹傓偄偝傫偺僽儘僌乿偱STM32側偳ARM宯偺偍偡偡傔奐敪娐嫬乮彍偔弶怱幰乯偭偰偺偑偁偭偰偦偙偐傜偺儕儞僋偱丄Cortex-M3偭偰偺偼ARMv7-m傾乕僉偭偰偙偲偑傢偐傝傑偟偨両
ARMv7偭偰ARM7偺偙偲偠傖側偄偐丅
偪側傒偵ARMv6-m偭偰偺偼Cortex-M0+丄ARMv7e-m偭偰偺偼Cortex-M4傜偟偄偱偡丅
偲偄偆偙偲偱丄armv7-m偺僨傿儗僋僩儕乕偵偁傞儔僀僽儔儕傪儕儞僋偟偨傜摦偒傑偟偨丅丂偄傗丄傑偠偱柍抦偭偰嵾偱偡偹丅
摦偒弌偟偨偺偼偄偄偺偩偗偳丄malloc偼傑偲傕偵摦偒傑偣傫丅
偁偁偱傕側偄偙偆偱傕側偄偲帋峴嶖岆偡傞偙偲偟偽傜偔丅
偳偆偵傕偍偐偟偄偙偲偑偄偔偮偐丅
丒奜晹曄悢end偺屻傠偵偄偔偮偐偺曄悢椞堟偑攝抲偝傟偰偟傑偭偰偄傞丅
丒sbrk()偱尰忬偺僸乕僾愭摢傾僪儗僗傪庢摼偡傞偲RAM僄儕傾奜偵側偭偰偄傞丅
偹傓偄偝傫偺僽儘僌偱偼乽_end乿偲偁偭偨奜晹曄悢偱偡偑丄newlib撪偺僜乕僗傪妋擣偟偨偲偙傠丄嶲徠偟偰偄傞偺偼乽end乿偱偟偨丅
峏偵偼嶲徠偟偰偄傞偺偼end偺撪梕偱偼側偔丄end偺傾僪儗僗丅
偮傑傝end偼.bss僙僋僔儑儞偺嵟屻偱側偗傟偽側傝傑偣傫丅
偙傟偼儕儞僇僗僋儕僾僩偺栤戣偱偡丅
.bss僙僋僔儑儞偺屻傠偵._usrstack偲偄偆僙僋僔儑儞偑愝掕偝傟偰偄偨偺偱偡偑丄僗僞僢僋偼RAM僄儕傾偺堦斣屻傠偵1024byte妋曐偝傟偰偄偰偦偙偐傜巊傢傟偰偄傞傛偆偱偡丅
偙偺僗僞僢僋偑偳偆巊傢傟偰偄傞偺偐尒傞偺傕幚偼嬯楯偟傑偟偨丅
10屄偔傜偄偺char宆曄悢傪妋曐偟偰傢偐傝傗偡偄僨乕僞傪彂偒崬傫偱傒傞偲偄偆偙偲傪傗偭偰傒偨偺偩偗偳丄儊儌儕僟儞僾偟偰傕尒摉偨傜側偄丅
偙傟偼乽巊傢傟偰偄側偄曄悢乿偲偄偆偙偲偱嵟揔壔偱嶍彍偝傟偰偟傑偭偰偄傑偟偨丅volatile char宆偱愰尵偟偰傗偭偲尒偊傑偟偨丅
嵟揔壔嫲傞傋偟丅
偲偄偆偙偲偱丄._usrstack偲偄偆僙僋僔儑儞偼巊傢傟偰偄側偄偲抐掕偟偰嶍彍丅
僸乕僾椞堟偲偄偆偺傕柧妋偵愰尵偡傞昁梫偼側偄偲巚偄傑偟偰丄偙偺傛偆偵偟傑偟偨丅
.bss :
{
. = ALIGN(4);
_sbss = .;
*(.bss)
*(COMMON)
. = ALIGN(4);
_ebss = . ;
} >RAM
.heap(NOLOAD) :
{
end = . ;
*(.heap)
} >RAM
偙傟偱僔儞儃儖僥乕僽儖偼偙傫側晽偵側傝傑偟偨丅
20000b30 B errno
20000b34 B _ebss
20000b34 ? end
2000fc00 A __Stack_Init
20010000 A _estack
f1e0f85f a BootRAM
僔儞儃儖嬫暘偑乽?乿偵側偭偰偟傑偄傑偟偨偑丄.bss偺嵟屻偵側傝傑偟偨丅
偟偐偟丄偙傟偱傕傗偭傁傝malloc偼摦偒傑偣傫丅僸乕僾偺愭摢嵗昗偼偍偐偟偄傑傑偱偡丅
偱丄newlib偺僜乕僗傪尒偰堘榓姶偑偁偭偨晹暘偵拝栚丅採嫙僜乕僗傪媈偄偨偔側偐偭偨偺偱尒偰尒偸傆傝傪偟偰偄傑偟偨偑丄巇曽側偄丅
_sbrk()撪偱僸乕僾偺傾僪儗僗傪娗棟偟偰偄傞static側曄悢偑偁傞偺偱偡偑丄偙偺抣偑NULL偺帪偵end偺傾僪儗僗傪戙擖偡傞偲側偭偰偄傑偡丅偙傟偭偰弶婜忬懺偺偙偲偩傛偹丅偱傕偙偺曄悢弶婜壔偝傟偰偄側偄偺偱晄掕抣側偼偢丅
偲偄偆偙偲偱丄RAM傪慡晹僛儘偱杽傔恠偔偟偰偐傜僾儘僌儔儉傪摦偐偟偰傒傞偲丄malloc摦偒傑偟偨丅
偪傖傫偲end偺屻傠偵妋曐偝傟偰偄傞條巕偑尒偊傑偟偨丅
sbrk()偱庢摼偡傞傾僪儗僗傕惓忢偱偡丅丂偙傟偐偀乣丅
偲偄偆帠偱newlib偺嵟怴斉2.5.0傪棊偲偟偰偒偰傒傑偟偨偑丄撪梕偑曄傢偭偰偄側偐偭偨偺偱僜乕僗傪偪傚偙偭偲廋惓丅
static char * heap_end = NULL;
愰尵帪偵NULL偱弶婜壔偡傞偩偗偱偡丅偦偟偰僐儞僷僀儖丅
mkdir build
cd build
../configure -target=arm-none-eabi -prefix=/opt/newlib --enable-multilib --enable-interworks
make; make install
嵟怴斉偩偲arm-v8偲偐偵傕懳墳偟偰偄傞傒偨偄偩偗偳懳墳偑拞搑敿抂傜偟偔傾僙儞僽儔偱僄儔乕偑弌傑偡丅
僜乕僗尒偰傕arm-v8岦偗偺婰弎偑偁傞傢偗偠傖側偄偺偱arm-v8偺僨傿儗僋僩儕傪徚偟偰丄柍帇偟傑偟偨丅
偙偺儔僀僽儔儕偵嵎偟懼偊偨偲偙傠丄儊儌儕乕傪墭偟偰傕偪傖傫偲摦偒弌偟傑偟偨丅
傔偱偨偟傔偱偨偟丅
偲巚偄傑偟偨偑丄malloc偺堦斒揑側摦偒偲堘偆偙偲偵崱婥偯偄偨丅
僱僢僩偱挷傋傞偲丄malloc偼枹巊梡椞堟傪巊偆丅偦偺帪偵巊偆椞堟傪寛傔偰乮heap乯偦偙偐傜儊儌儕傪愗傝弌偡丅
heap偑懌傝側偔側傞偲sbrk()偱椞堟傪奼戝偟偰偄偔丅
偲側偭偰偄傞偑丄newlib偺_sbrk()偲儊儌儕乕偺巊梡忬嫷傪尒傞偲丄heap偺愭摢偼.bss僙僋僔儑儞傪愭摢偲偟偰丄僗僞僢僋僄儞僪傑偱偺椞堟丅偙傟偑heap偵憡摉偡傞丅
sbrk()偱堷悢偵梕検傪擖傟傞偲丄尰忬偺heap愭摢傪堷悢暘偩偗偢傜偡丅偮傑傝heap偑彫偝偔側傞丅
偲側偭偰偄傞丅
free()偺摦偒傕枹妋擣丅malloc偱妋曐偟偨椞堟傪free偱夝曻偟偨傜偪傖傫偲枹巊梡椞堟偵娨尦偝傟傞偺偩傠偆偐丅
偝傟側偄偲崲傞傫偩偗偳側丅
椞堟偺棙梡娗棟偼heap偺娗棟偲偼傑偨暿偺傛偆側偺偱free()偱夝曻偟偨傜heap偺愭摢偑曄傢傞傢偗偱偼側偝偦偆偩偑丅
偪傚偭偲晄埨傪巆偟偮偮丄STM32偱malloc僾儘僕僃僋僩偼堦扷暵枊偲偟傑偡丅
師偼丄偲偆偲偆幚婡幚憰偐偲偄偆偲偦傫側偵娒偔偁傝傑偣傫偱偟偨丅
崱傑偱巊偭偰偄偨Cortex-M3偼拞梕検乮Medium-density乯偲屇偽傟傞傕偺偱FLASH:128kbyte RAM:20kbyte偟偐偁傝傑偣傫丅
malloc傪慻傒崬傫偩搑抂掕媊嵪曄悢偑傕偺偡偛偔憹偊偰丄偁偭偲偄偆娫偵20kbyte偺梕検傪怘偄恠偔偟偰偟傑偄傑偟偨丅FLASH傕枮攖偱偡丅
摦偐偟偰傒傞偵偼Cortex-M3戝梕検乮High-density FLASH:512kbyte RAM:64kbyte乯偵堏峴偟側偗傟偽側傝傑偣傫丅
傕偟偔偼Cortex-M4(FLASH:1Mbyte RAM:192kbyte)偵堏峴丅
娫堘偄側偔帪戙偼M4側偺偱偡偑丄偒偭偲儁儕僼僃儔儖偑曄傢偭偰偰娙扨偵棫偪忋偑傜側偄偵寛傑偭偰傞偺偱M3(High-density)偱偲偵偐偔摦偐偟偰傒傞帠偵偟傑偡丅
malloc傕摦偄偨帠偩偟丄偝偔偭偲忔偭偗偰傒傑偟偨丅
懡暘摦椡妛僼傿儖僞乕偼儊儌儕乕検偐傜嵹傜側偄偩傠偆偐傜傑偢偼幙揰寁嶼梡偺儘儃僢僩儌僨儖傪嵹偣偰傒傑偡丅偦偺懠昁梫偵側傞娭悢孮傕嵹偣偪傖偄傑偡丅
寢壥丄STBee-MINI偺20Kbyte偺RAM偱偼儘儃僢僩儌僨儖偝偊嵹傜側偄丅帋嶼偱偼儘儃僢僩儌僨儖偔傜偄偼妝彑偲巚偭偰偄偨偺偩偗偳丄libnosys傪儕儞僋偟偨偙偲偱偄傠偄傠曄悢偑昁梫偵側偭偨傒偨偄偱偡丅
憗懍STBee偵愗傝懼偊偱偡丅STBee偼Coron傛傝婎斅僒僀僘偑偱偐偄偺偱崱屻偙傟偱恑傔傞偙偲偼愨懳偁傝摼側偄偺偱偡偑丄憗偔摦偐偟偰傒偨偄偲偄偆偦偺堦揰偱嵹偣偰傒傑偡丅RAM傕64Kbyte偁傟偽戝忎晇偩傠偆丅
儁儕僼僃儔儖傪堏偝側偒傖側傜側偄偺偱傔傫偳偔偝偄側乕偲巚偭偰偄偨偺偱偡偑丄婎斅偵偁傜偐偠傔幚憰偝傟偰偄傞LED偵傾僒僀儞偝傟偰偄傞億乕僩偑偑堘偆偩偗偱偁偲偼慡晹堦弿偱偟偨丅
偝偰丄戞堦抜奒
栚昗ZMP楍偺惗惉偼擄側偔僋儕傾丂佀丂malloc偼偪傖傫偲摦偄偰傞傜偟偄丅
戞擇梊尒僨乕僞嶌惉
偙偙偱僴儅偭偨丅
偨傇傫丄嬥梛擔夛幮偐傜婣偭偰屵慜3帪偔傜偄傑偱傗偭偰慡慠傢偐傜傫偐傜怮傞丅師偺擔傕偛偼傫怘傋傞埲奜偼偢乕偭偲僶僌扵偟偱丄偍偦傜偔偼20帪娫偔傜偄僴儅偭偨丅傑偀懪偮庤偑巚偄晜偐偽側偔偰摨偠偙偲傪偖傞偖傞孞傝曉偟偰偄傞帪娫傕娷傔偰偱偡偗偳丅
幙揰儌僨儖偱ZMP傪寁嶼偟偰傞偲偙傠偱曄悢偑nan偵側傞丅偙偙偼儕僇乕僔僽偱屇傃弌偟偨傝偟偰傔傫偳偔偝偄偲偙側偺偱僨乕僞慡晹揻偒弌偝偣偨傝偟偰偍偐偟偄偲偙傠丄偍偐偟偄僨乕僞傪偁傇傝弌偦偆偲偟偨傫偩偑丄儕僇乕僔僽偩偐傜僄儔乕偑弌偨偺偑偳偺抜奒側偺偐挷傋傞偺傕戝曄偱丄偱傕偳傫偳傫偳傫偳傫慿偭偰偲偆偲偆弴塣摦妛娭悢偺拞偺擇墌偺岎揰傪寁嶼偡傞偲偙傠偱晄怰側摦偒傪敪尒丅 巚偄偭偒傝偔偩傜側偄僶僌偑巆偭偰偨丅(^)
偦偺僶僌偺偍偐偘偱僄儔乕僼儔僌偑棫偭偰傞偺偵僼儔僌傪張棟偟偰偄側偄丅偦偺忋偵僄儔乕婲偙偟偰傕偪傖傫偲抣偑曉偭偰偔傞傛偆偵尒偊偰偨
慜夞偺僨乕僞傪尒偪傖偆偺偱彮偟偩偗抣偑堘偆偼偢側傫偩偗偳彮偟偩偐傜嫇摦晄怰偵傑偱側傜側偄傫偩側丅
偪傖傫偲僄儔乕張棟偟偰抣偼僋儕傾偵偟偰偍偐側偄偲僟儊偱偡偹乕丅
偙偺曈傝偑慺恖僾儘僌儔儅乕偺僟儊側偲偙偩側丅戞嶰幰儗價儏乕偲偐偟側偄偟丄僠僃僢僋儕僗僩偲偐偁偭偨傜堷偭偐偐傞偲偙傠偩傠偆丅
戞嶰抜奒
偲偆偲偆摦椡妛僼傿儖僞乕晹偲丄曗惓抣壛偊偰嵟廔揑側儌乕僔儑儞傪惗惉偡傞僙僋僔儑儞偵庢傝偐偐傞丅
偙偙偐傜愭偼梊尒僨乕僞嶌惉偲傎傏摨偠偙偲傪傗偭偰傞偩偗側偺偱栤戣側偔摦偔偼偢丅側傫偩偗偳丄傑偭偨偔摦偐側偄丅
偮傑傝丄妱傝崬傒婜娫拞偵儌乕僔儑儞惗惉偱偒側偄傫偱偡偹丅
崱偺峔惉偼丄20ms廃婜偱妱傝崬傒偑偐偐傝丄僙儞僒乕庢傝崬傒偲僒乕儃巜椷傪峴偄傑偡丅
偱偒傞偩偗儁儕僼僃儔儖偵撍偒曻偟張棟偡傞傛偆偵DMA傪巊偆傛偆偵偟偰偄偰儖乕僾傪夞偟偰偺僂僃僀僩偲偐偼嵟彫尷偵偟偰偄傑偡丅
偱偡偺偱妱傝崬傒帪娫偼傎偲傫偳側偄偺偱偡偑丄偦偺巆傝帪娫偼儊僀儞儖乕僾偑帩偭偰傑偡丅
廳偄儌乕僔儑儞惗惉傪峴偭偨偁偲丄僙儞僒乕僨乕僞傪庢摼偟偰僒乕儃楍偵僨乕僞傪憲傞偲偄偆偺偼柍杁偱偟偨丅
帪娫偑側偔偰張棟偑攋偨傫偟偰傑偡丅
偱偼丄帪娫傪帩偭偰傞儊僀儞儖乕僾偱張棟傪偡傞傛偆偵偟傑偟傚偆丅
僼儔僌傪巊偭偰丄儌乕僔儑儞僨乕僞偺嶌惉巜帵傪惪偗偰丄儊僀儞儖乕僾偱嶌惉丄姰惉偟偨傜姰椆僼儔僌偱妱傝崬傒僗儗僢僪偵捠抦偟傑偡丅
偱丄摦偒傑偟偨両丂偑丄娫偵崌偭偰側偄丅僽儕僽儕尵偄側偑傜備偭偔傝摦偄偰傞丅帪娫傪帩偭偰傞儊僀儞儖乕僾偱傕張棟偑娫偵崌傢側偄傜偟偄丅
挷傋傞偲1僼儗乕儉敳偗偰傞偺偱梊掕摦嶌偺攞偺抶偝偱摦偄偰傞傢偗偱曕偗傞傢偗側偄偱偡偹丅
偡傞偲丄懸偰傛丅寁夋ZMP偺曄峏懳墳側傫偰愨懳柍棟傗傫両
偳傟偔傜偄柍棟側傫偩傠偆丠偲偄偆偙偲偱梊尒僨乕僞峔抸偵偐偐傞帪娫傪寁偭偰傒偨偲偙傠乮妱傝崬傒廃婜扨埵偱偺峳偭傐偄應掕偱偡乯
40僐儅偺梊尒僨乕僞傪嶌傞偺偵0.5昩偐偐傝傑偡丅梊尒僨乕僞偺嶌傝捈偟偡傞堄枴側偄傗傫丅丅
怳傝曉偭偰峫偊傞偲丄嵟弶偵STM CortexM3CPU偱僒乕儃傪摦偐偟偨偺偼僔僌儅偱偡丅嵟弶偼SEMB1200偱摦偐偟偰偨傫偩偗偳丄僔僌儅偩偲摦椡妛偲偐梫傜側偄偺偱Coron佀STBee-MINI偱摦偐偟偰傑偟偨丅偦偺帪偼1僐儅偺帪娫偱5僐儅暘偺IK寁嶼偑偱偒偰戝偟偨傕傫偩側乕偲巚偭偰偨傫偱偡偑丄偁傟偼斾妑揑娙扨側IK寁嶼傪6懌暘傗偭偰偨偩偗側偺偱摦椡妛僼傿儖僞乕偲偼寁嶼検偺寘偑堘偆丅
偁傟偱5僐儅側傫偩偐傜M3偱摦椡妛僼傿儖僞乕摦偐偣傞傢偗側偄傗傫丅傾儂偱偡偹丅
傗偼傝堦斣帪娫偑偐偐傞偺偼幙揰儌僨儖傪巊偭偨ZMP偺嶼弌丅寁夋廋惓晅偒偺摦椡妛僼傿儖僞乕偱摦偐偦偆偲偡傞偲1僼儗乕儉帪娫偱偙偺寁嶼傪俁夞埲忋偱偒側偗傟偽側傜側偄丅捠忢偼侾夞偱偡偑丄廋惓偱俀夞傗傞偲偟偨傜係侽僼儗乕儉偺梊尒僨乕僞嶌惉偵俀侽僼儗乕儉昁梫丅
寢峔晘嫃崅偄偱偡偹丅
寁嶼偺傎偲傫偳偑晜摦彫悢揰墘嶼側偺偱M4偵偡傟偽偢偄傇傫摼傪偡傞偲偼巚偆偺偱偡偑丄偳偺掱搙傑偱峴偗傞偐丅丅
M3佀M4偼儁儕僼僃儔儖廃傝偑庒姳曄傢偭偨偲晽偺偆傢偝偵暦偄偨偺偱庤傪弌偟偁偖偹偰偄偨偺偱偡偑丄Standard Peripheral Library巊偊偽嵎暘傪媧廂偟偰偔傟傞偲偐側傜偆傟偟偄傫偩偗偳側乕丅
M4傪棫偪忋偘偮偮丄傕偆堦偮壽戣傪偙側偡昁梫偑偁傝傑偡丅
偙傟偼僔儈儏儗乕僔儑儞偱偼柍帇偟偰偄偨僒乕儃摿惈偲偐婡夿揑摿惈丅
傎傫偲偼僔儈儏儗乕僔儑儞忋偱僒乕儃摿惈傪嵞尰偟偰偦偺僼僅儘乕晹暘傕嶌傝忋偘傞偲偄偆偺傕柺敀偄乮偲偄偆偐丄偦傟偑僔儈儏儗乕僔儑儞偺杮夰偩偑乯偲巚偭偨偺偱偡偑丄惓捈戝曄偩偟丄杮婡懱偑婛偵偁傞偺偱尰暔巊偆偲偙傠偐側偲丅
崱夞偺儔儉僟偺懌峔憿偼捈岎暘棧傪栚揑偲偟偨擇廳旕暯峴係愡儕儞僋偱偡丅
偦偺偨傔儕儞僋幉偑偁偪偙偪偵偁偭偰丄偦傟偩偗偱嶌傝偑娒偔側偭偰傑偡丅峏偵偼婡懱廳検偵懳偟偰峔惉晹嵽偺崉惈傕廫暘偱偼側偄側偀偲巚偭偰傑偡丅
曄懺揑偙偩傢傝婡夿僄儞僕僯傾偱偁傞恀峀偝傫偵尒偣偨傝偟偨傜僈儔僋僞埖偄偝傟傞儌僲偱偡丅
偱偡偑丄偙傟偵偼慱偄偑偁傝傑偟偰丄偦偺慱偄偼壗偐偲偄偆偲乽徴撍徴寕乿偱偡丅
曕偐偣偰栤戣偵側傞偺偼旼偺僟儗偲偐屢娭愡儘乕儖偺僟儗偲偐怓乆偁傝傑偡偑丄拝抧帪偺潧偹偑偁傝傑偡丅
潧偹偪傖偆偲寁嶼捠傝偵摦偄偰偔傟側偄傫偱偡傛偹丅
僕儍僀儘僙儞僒乕偱怳摦媧廂偟偨傝偲偐怓乆曽朄偼偁傞傫偱偡偑丄婡夿揑偵潧偹傪媧廂偟偨偄偲偄偆偺偑捈岎暘棧偺恀堄偺堦偮偱偡丅
偟偐偟憡斀偡傞偙偲偱偡偑丄懌慡懱偱斀敪僄僱儖僊乕傪媧廂偡傞偲偄偆偙偲偼娭愡妏搙偺嵞惗惛搙傪媇惖偵偡傞偲偄偆偙偲偵側傝傑偡丅
偙偺暃嶌梡傪梷偊傞偨傔偵曗彏婡峔偑昁梫側傝傑偡丅
寁嶼捠傝偺娭愡妏搙偵側傞傛偆偵曗彏傪壛偊傞偙偲偱潧偹傪媧廂偟丄寁嶼曕峴偺惛搙傪崅傔傞偨傔偺嵞惗惛搙傪妋曐偡傞偲丅
慜夞偺儔儉僟偱偼偙偺曗彏偵娭愡壸廳寁嶼傪巊梡偟傑偟偨丅
娭愡偺僟儗偼娭愡偵偐偐傞壸廳偱寛傑傝傑偡丅壸廳偼F=Ma 側偺偱幙検偲壛懍搙乮娭愡偩偐傜姷惈儌乕儊儞僩偲妏壛懍搙偱偡偑乯偱寛傑傝傑偡丅
奺娭愡偼楢摦偟偰偄側偄偺偱ZMP寁嶼傛傝峏偵傔傫偳偔偝偄寁嶼偑昁梫偱偡丅
偦傟偵懳偟偰捈岎暘棧宆偱偁傞崱夞偺儔儉僟偼悅捈壸廳偵懳偡傞僒乕儃偼侾偮丄悈暯壸廳偵懳偡傞僒乕儃偑侾偮偱偡丅
摨偠傛偆偵娭愡壸廳傪寁嶼偡傞偺傕壜擻偱偡偑丄寁嶼検偼彮偟懡偔側傞偔傜偄偱偡偺偱傗偭傁傝戝曄丅
峏偵偼愭偺僈儔僋僞偺審偱彂偄偨傛偆偵偁偪偙偪偱壸廳偑敳偗偨傝椑偑偨傢傫偩傝偟偰偄傞壜擻惈偑崅偔偰幉壸廳寁嶼抣偵怣溸惈偑側偝偦偆丅
偲偄偆偙偲偱悅捈偼ZMP偱戙懼偊偟偰傒傛偆偲巚偄傑偡丅
ZMP偲尵偭偰傕曅懌偱巟偊偰偄傞偐丄椉懌偱巟偊偰偄傞偑椉懌傊偺壸廳偑嬒摍偐晄嬒摍壔偐丠偔傜偄偱拞娫揑側悢抣傪巊偆偺偼椉懌巜帵偱壸廳偑晄嬒摍側応崌偔傜偄偱偡偐偹丅
悈暯偼帺廳偲悈暯壛懍搙偱偡偑丄姷惈偮偄偰傞偐傜偁傫傑傝娭學側偄偐側乕偲巚偭偰傑偡丅幚尡偟偰傒偰梫曗彏偐偳偆偐敾抐偑昁梫偐側丅
幚尡偟偨偄偺偩偑丄ZMP寁嶼傪偡傞偲張棟僆乕僶乕偵側偭偰偟傑偆偺偱丄堦扷偼寁夋ZMP傪擖椡偲偟偰曗惓抣傪寛掕偟偰傒傑偡丅
寁夋ZMP偐傜廳怱揰偺塣摦傪摫偔偵偼懡尦曽掱幃傪夝偐側偗傟偽側傜側偄偗偳丄廳怱揰偺塣摦偐傜ZMP傪寁嶼偡傞偺偼擄偟偔偁傝傑偣傫丅
偙傟傪巊偭偰丄廳怱揰偺摦偒偑偳偺傛偆側ZMP偺摦偒傪惗傓偐傪偪傚偭偲妋偐傔偰傒傑偡丅
侾丏儕僯傾
捈慄偱摦偐偡偲丄掕懍堏摦帪偼壛懍搙偼僛儘側偺偱ZMP偼廳怱揰偺恀壓丅摦嶌奐巒帪偲摦嶌掆巭帪偵戝偒側壛懍搙偑敪惗偡傞偺偱ZMP偑戝偒偔棎傟傑偡丅
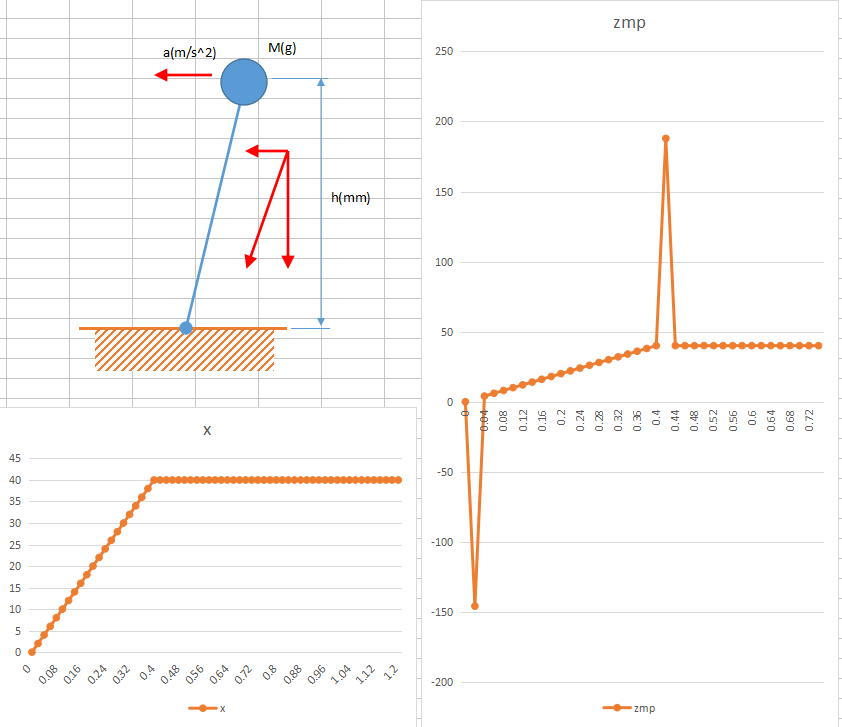
俀丏僒僀儞僇乕僽
sin()偺俀奒旝暘偼-sin()偵側傞偺偱偙傫側晽偵丅ZMP婳摴偵嬤偦偆偵尒偊偰壛懍搙偱尒傞偲慡慠堘偄傑偡丅
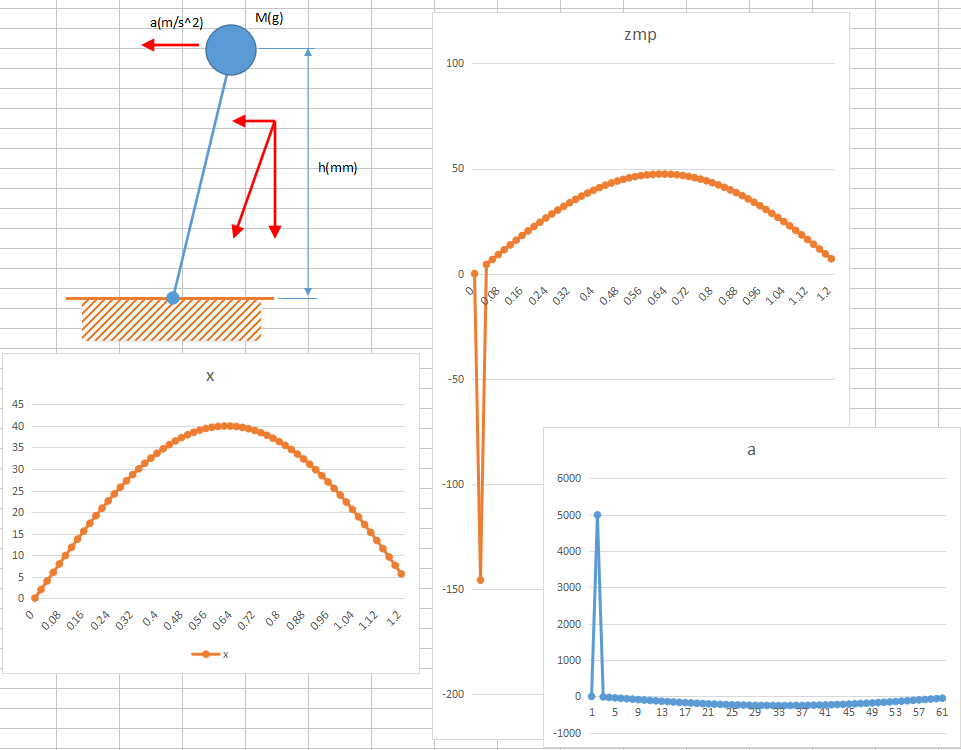
俁丏寁夋ZMP偐傜偺廳怱揰婳摴
壛懍搙傪尒傞偲丄愙抧揰偵ZMP傪巆偟偮偮壛懍搙傪忋偘偰偄偒丄ZMP愗傝懼偊億僀儞僩偐傜偼壛懍搙傪壓偘偰丄摉偨傜側愙抧揰偵廳怱揰傪嬤偯偗偰偄偔偡偽傜偟偄丅
傕偆偦傠偦傠儁乕僕傪愗傝懼偊傞崰偐側乕丅